使用 DBeaver 连接 Spark
前言
spark 通过 kyuubi 连接
1.准备驱动
hive-jdbc-3.1.3-1-standalone.jar 下载地址
2.配置hosts
DBeaver 所在的 Windows 主机需要添加 hosts 映射,映射信息可以在 ambari 集群中查看。
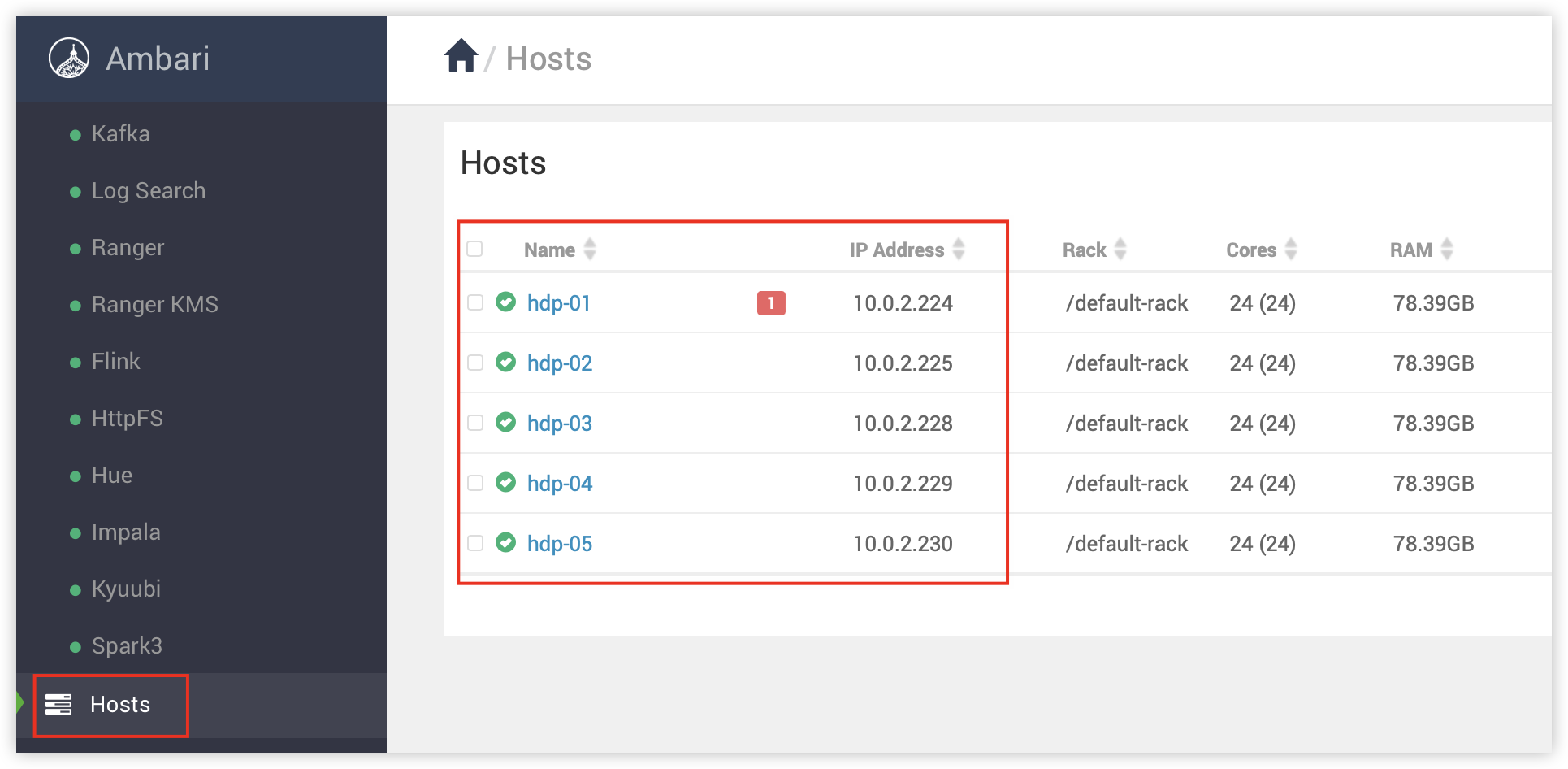
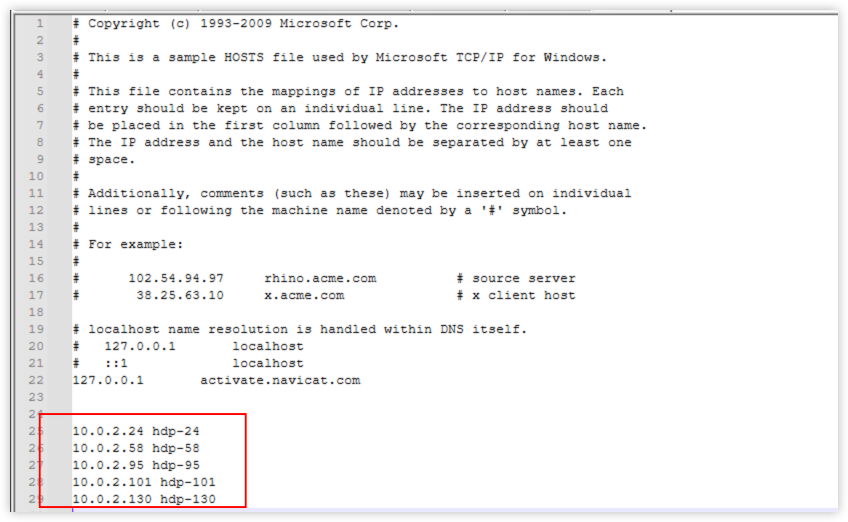
路径 C:\Windows\System32\drivers\etc\hosts
3.Kyuubi 连接准备
在Ambari 中选择 Kyuubi ,复制kyuubi 连接。
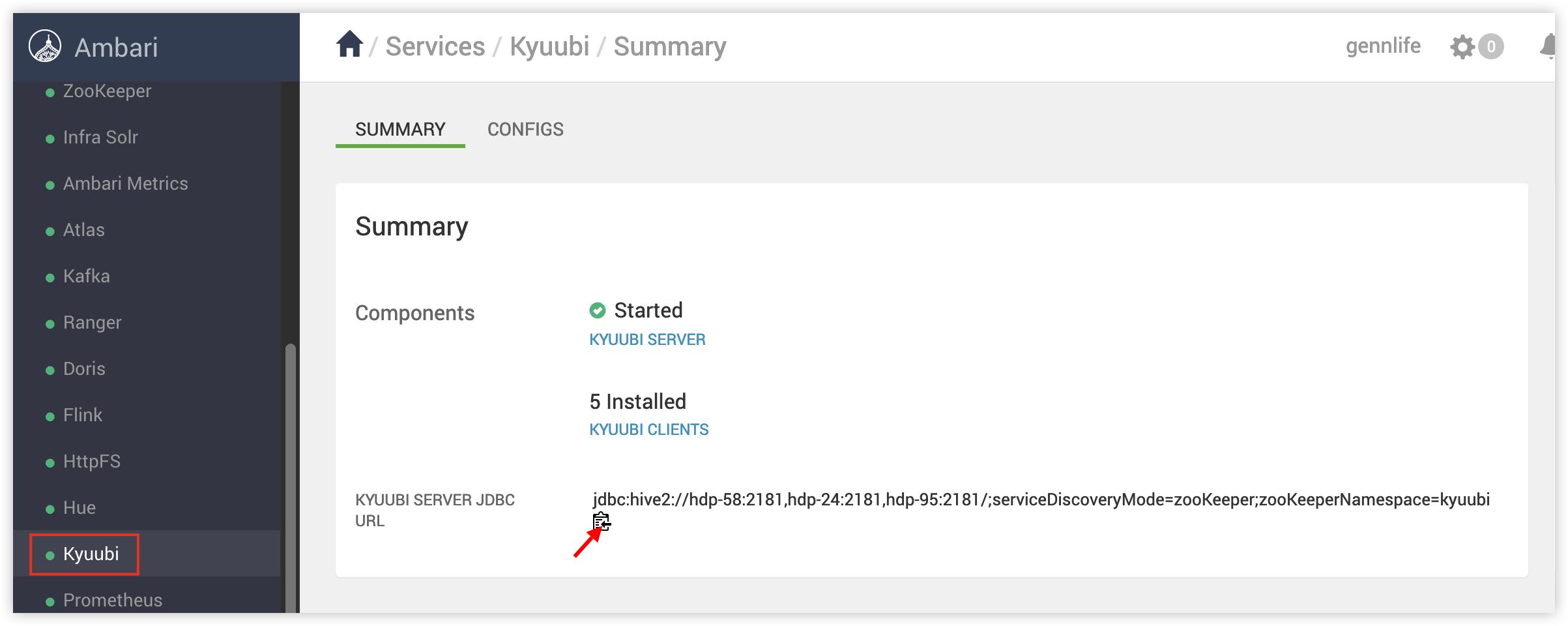
jdbc:hive2://hdp-58:2181,hdp-24:2181,hdp-95:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=kyuubi
此时的连接还不能直接使用,要添加模式,和内存参数,直接在后面追加。
#kyuubi.engine.share.level=CONNECTION;spark.executor.memory=4g
完整的 url 参考
jdbc:hive2://hdp-58:2181,hdp-24:2181,hdp-95:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=kyuubi#kyuubi.engine.share.level=CONNECTION;spark.executor.memory=4g
4.配置DBeaver
1.新建数据源
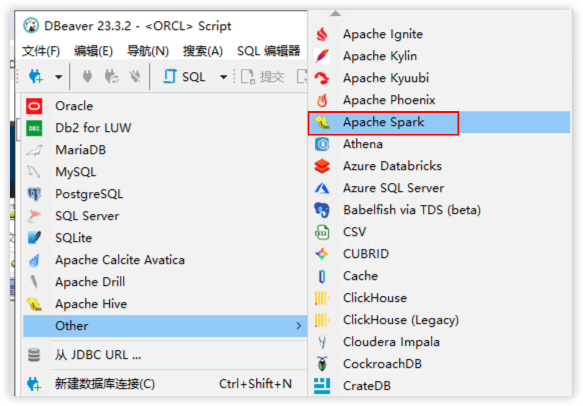
2.填写配置信息
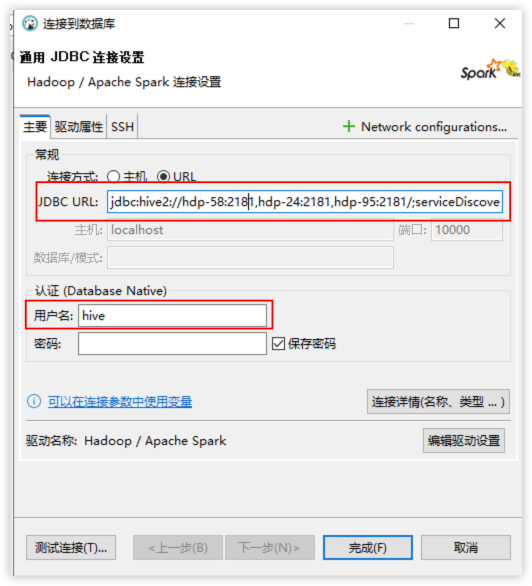
如果DBeaver 版本比较低,没有 URL 配置,就直接配置主机,端口号不要填写。
hdp-58:2181,hdp-24:2181,hdp-95:2181/;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=kyuubi#kyuubi.engine.share.level=CONNECTION;spark.executor.memory=4g
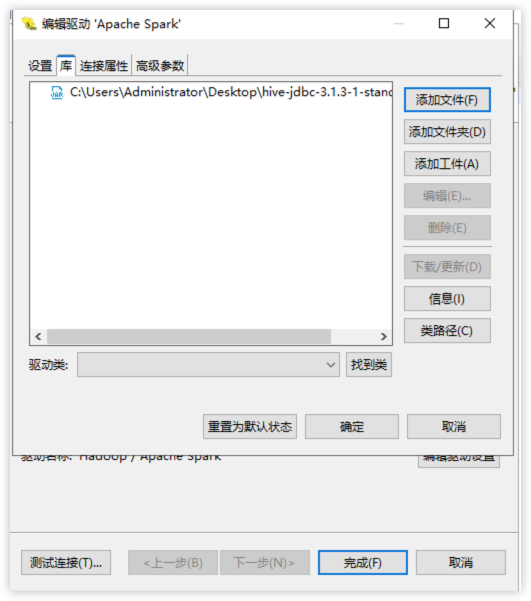
3.配置驱动
编辑驱动配置 → 库 → 添加文件, 选择准备好的驱动
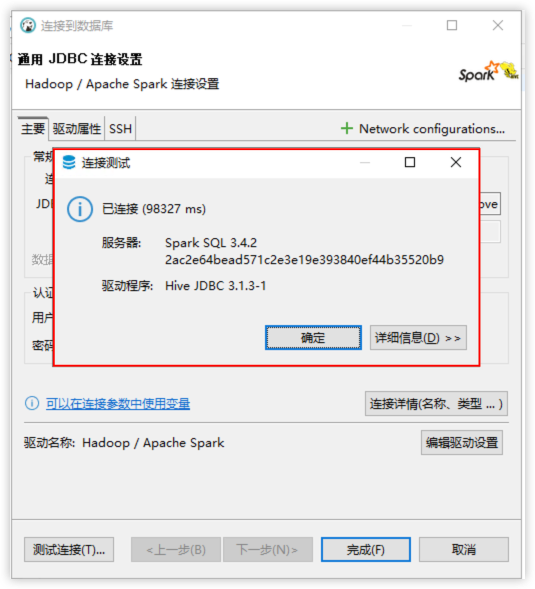
测试连接
4.查看库表
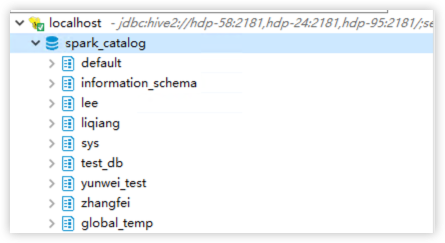
到此配置就结束了。如果因为内存导致数据无法查询或者任务无法执行,需要修改 kyuubi 连接里 spark.executor.memory=4g 提升内存,重新连接。