Doris
Apache Doris(前身为Palo)是一款开源的分布式列式存储计算引擎,用于快速查询和分析大规模数据
Apache Doris 简介
Apache Doris 是一款基于 MPP 架构的高性能、实时的分析型数据库,以高效、简单、统一的特点被人们所熟知,仅需亚秒级响应时间即可返回海量数据下的查询结果,不仅可以支持高并发的点查询场景,也能支持高吞吐的复杂分析场景。
整体架构和技术特点
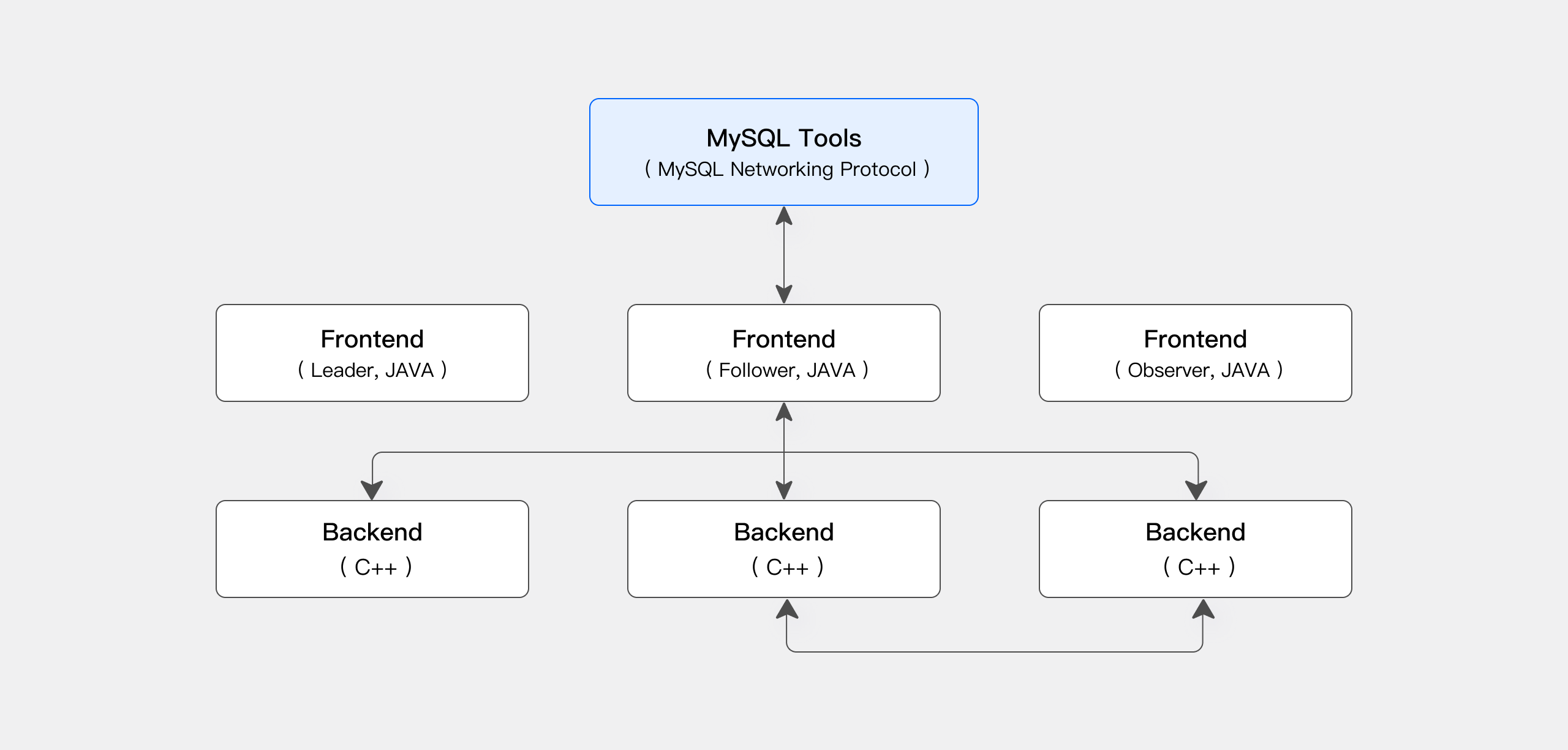
Apache Doris 的整体架构非常简单,如下图所示,只有两类进程:
- Frontend(FE):主要负��责用户请求的接入、查询解析规划、元数据的管理、节点管理相关工作。
- Backend(BE):主要负责数据存储、查询计划的执行。
这两类进程都是可以横向扩展的,单集群可以支持到数百台机器,数十 PB 的存储容量。并且这两类进程通过一致性协议来保证服务的高可用和数据的高可靠。这种高度集成的架构设计极大地降低了一款分布式系统的运维成本。
使用接口
Apache Doris 采用 MySQL 协议,高度兼容 MySQL 语法,支持标准 SQL,用户可以通过各类客户端工具来访问 Apache Doris,并支持与 BI 工具的无缝对接。Apache Doris 当前支持多种主流的 BI 产品,包括不限于 Smartbi、DataEase、FineBI、Tableau、Power BI、Apache Superset 等,只要支持 MySQL 协议的 BI 工具,Apache Doris 就可以作为数据源提供查询支持。
存储引擎
在存储引擎方面,Apache Doris 采用列式存储,按列进行数据的编码压缩和读取,能够实现极高的压缩比,同时减少大量非相关数据的扫描,从而更加有效利用 IO 和 CPU 资源。
Apache Doris 也支持比较丰富的索引结构,来减少数据的扫描:
-
Sorted Compound Key Index,可以最多指定三个列组成复合排序键,通过该索引,能够有效进行数据裁剪,从而能够更好支持高并发的报表场景
-
Min/Max Index:有效过滤数值类型的等值和范围查询
-
BloomFilter Index:对高基数列的等值过滤裁剪非常有效
-
Inverted Index:能够对任意字段实现快速检索
在存储模型方面,Apache Doris 支持多种存储模型,针对不同的场景做了针对性的优化:
-
聚合模型(Aggregate Key Model):相同 Key 的 Value 列合并,通过提前聚合大幅提升性能
-
主键模型(Unique Key Model):Key 唯一,相同 Key 的数据覆盖,实现行级别数据更新
-
明细模型(Duplicate Key Model):明细数据模型,满足事实表的明细存储
Apache Doris 也支持强一致的物化视图,物化视图的更新和选择都在系统内自动进行,不需要用户手动选择,从而大幅减少了物化视图维护的代价。
查询引擎
在查询引擎方面,Apache Doris 采用 MPP 的模型,节点间和节点内都并行执行,也支持多个大表的分布式 Shuffle Join,从而能够更好应对复杂查询。
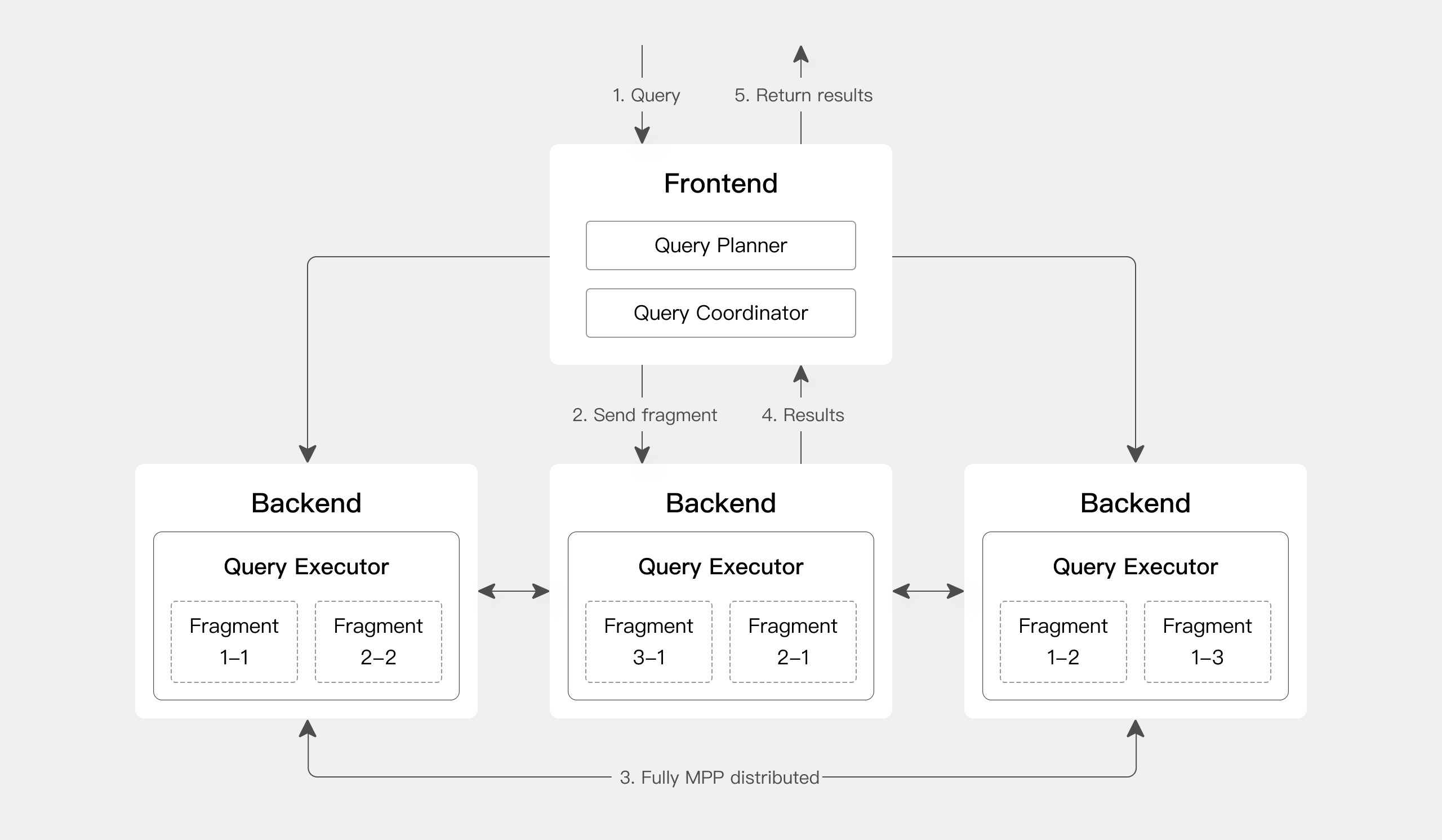
Apache Doris 查询引擎是向量化的查询引擎,所有的内存结构能够按照列式布局,能够达到大幅减少虚函数调用、提升 Cache 命中率,高效利用 SIMD 指令的效果。在宽表聚合场景下性能是非向量化引擎的 5-10 倍。
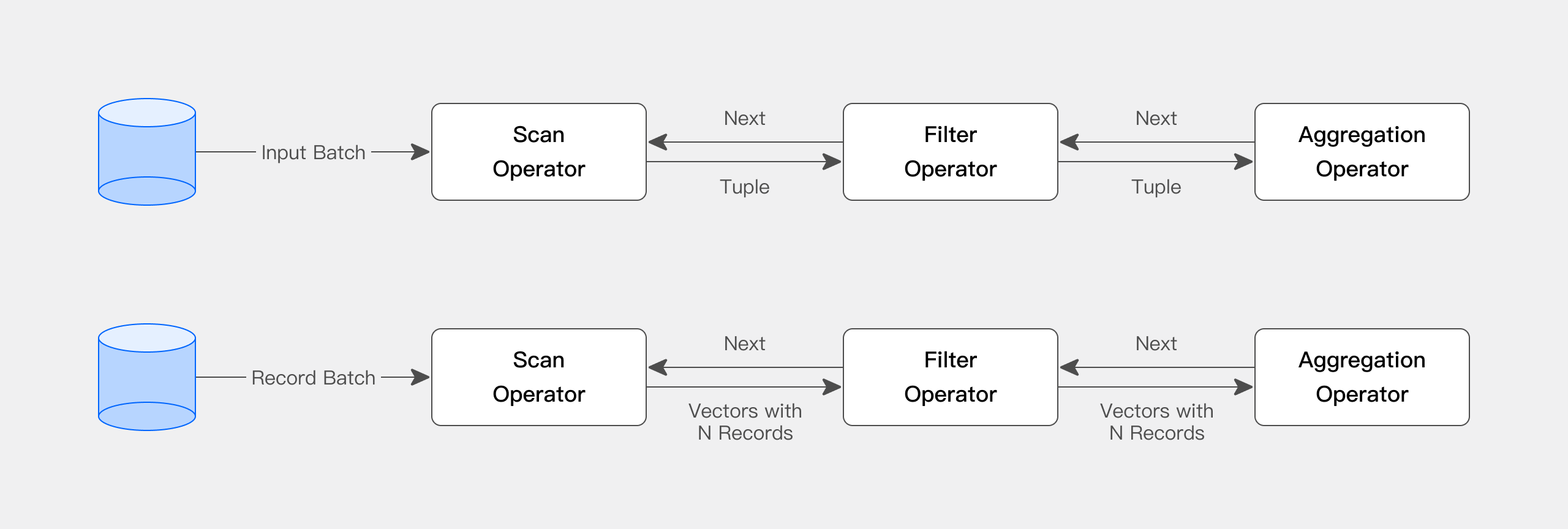
**Apache Doris 采用了自适应查询执行(Adaptive Query Execution)技术,**可以根据 Runtime Statistics 来动态调整执行计划,比如通过 Runtime Filter 技术能够在运行时生成 Filter 推到 Probe 侧,并且能够将 Filter 自动穿透到 Probe 侧最底层的 Scan 节点,从而大幅减少 Probe 的数据量,加速 Join 性能。Apache Doris 的 Runtime Filter 支持 In/Min/Max/Bloom Filter。
在优化器方面,Apache Doris 使用 CBO 和 RBO 结合的优化策略,RBO 支持常量折叠、子查询改写、谓词下推等,CBO 支持 Join Reorder。目前 CBO 还在持续优化中,主要集中在更加精准的统计信息收集和推导,更加精准的代价模型预估等方面。
索引类型
从加速的查询和原理来看,Apache Doris 的索引分为点查索引和跳数索引两大类。
点查索引
- 点查索引:常用于加速点查,原理是通过索引定位到满足 WHERE 条件的有哪些行,直接读取那些行。点查索引在满足条件的行比较少时效果很好。Apache Doris 的点查索引包括前缀索引和倒排索引。
-
前缀索引:Apache Doris 按照排序键以有序的方式存储数据,并每隔 1024 行数据创建一个稀疏前缀索引。索引中的 Key 是当前 1024 行中第一行中排序列的值。如果查询涉及已排序列,系统将找到相关 1024 行组的第一行并从那里开始扫描。
-
倒排索引:对创建了倒排索引的列,建立每个值到对应行号集合的倒排表。对于等值查询,先从倒排表中查到行号集合,然后直接读取对应行的数据,而不用逐行扫描匹配数据,从而减少 I/O 加速查询。倒排索引还能加速范围过滤、文本关键词匹配,算法更加复杂但是基本原理类似。(备注:之前的 BITMAP 索引已经被更强的倒排索引取代)
跳数索引
-
- 跳数索引:常用于加速分析,原理是通过索引确定不满足 WHERE 条件的数据块,跳过这些不满足条件的数据块,只读取可能满足条件的数据块并再进行一次逐行过滤,最终得到满足条件的行。跳数索引在满足条件的行比较多时效果较好。Apache Doris 的跳数索引包括 ZoneMap 索引、BloomFilter 索引、NGram BloomFilter 索引。
- ZoneMap 索引:自动维护每一列的统计信息,为每一个数据文件(Segment)和数据块(Page)记录最大值、最小值、是否有 NULL。对于等值查询、范围查询、IS NULL,可以通过最大值、最小值、是否有 NULL 来判断数据文件和数据块是否可以包含满足条件的数据,如果没有则跳过不读对应的文件或数据块减少 I/O 加速查询。
- BloomFilter 索引:将索引对应列的可能取值存入 BloomFilter 数据结构中,它可以快速判断一个值是否在 BloomFilter 里面,并且 BloomFilter 存储空间占用很低。对于等值查询,如果判断这个值不在 BloomFilter 里面,就可以跳过对应的数据文件或者数据块减少 I/O 加速查询。
- NGram BloomFilter 索引:用于加速文本 LIKE 查询,基本原理与 BloomFilter 索引类似,只是存入 BloomFilter 的不是原始文本的值,而是对文本进行 NGram 分词,每个词作为值存入 BloomFilter。对于 LIKE 查询,将 LIKE 的 pattern 也进行 NGram 分词,判断每个词是否在 BloomFilter 中,如果某个词不在则对应的数据文件或者数据块就不满足 LIKE 条件,可以跳过这部分数据减少 I/O 加速查询。
上述索引中,前缀索引和 ZoneMap 索引是 Apache Doris 自动维护的内建智能索引,无需用户管理,而倒排索引、BloomFilter 索引、NGram BloomFilter 索引则需要用户自己根据场景选择,手动创建、删除。
- 各种类型索引特点对比
| 类型 | 索引 | 优点 | 局限 |
|---|---|---|---|
| 点查索引 | 前缀索引 | 内置索引,性能最好 | 一个表只有一组前缀索引 |
| 点查索引 | 倒排索引 | 支持分词和关键词匹配,任意列可建索引,多条件组合,持续增加函数加速 | 索引存储空间较大,与原始数据相当 |
| 跳数索引 | ZoneMap 索引 | 内置索引,索引存储空间小 | 支持的查询类型少,只支持等于、范围 |
| 跳数索引 | BloomFilter 索引 | 比 ZoneMap 更精细,索引空间中等 | 支持的查询类型少,只支持等于 |
| 跳数索引 | NGram BloomFilter 索引 | 支持 LIKE 加速,索引空间中等 | 支持的查询类型少,只支持 LIKE 加速 |
索引设计
数据库表的索引设计和优化跟数据特点和查询很相关,需要根据实际场景测试和优化。虽然没有 "银弹",Apache Doris 仍然不断努力降低用户使用索引的难度,用户可以�根据下面的简单建议原则进行索引选择和测试。
- 最频繁使用的过滤条件指定为 Key 自动建前缀索引,因为它的过滤效果最好,但是一个表只能有一个前缀索引,因此要用在最频繁的过滤条件上
- 对非 Key 字段如有过滤加速需求,首选建倒排索引,因为它的适用面广,可以多条件组合,次选下面两种索引:
- 有字符串 LIKE 匹配需求,再加一个 NGram BloomFilter 索引
- 对索引存储空间很敏感,将倒排索引换成 BloomFilter 索引
- 如果性能不及预期,通过 QueryProfile 分析索引过滤掉的数据量和消耗的时间,具体参考各个索引的详细文档
数据模型
Doris 的数据模型分为 3 类:
- 明细模型(Duplicate Key Model):允许指定的 Key 列重复,Doirs 存储层保留所有写入的数据,适用于必须保留所有原始数据记录的情况。
- 主键模型(Unique Key Model):每一行的 Key 值唯一,可确保给定的 Key 列不会存在重复行,Doris 存储层对每个 key 只保留最新写入的数据,适用于数据更新的情况。
- 聚合模型(Aggregate Key Model):可根据 Key 列聚合数据,Doris 存储层保留聚合后的数据,从而可以减少存储空间和提升查询性能;通常用于需要汇总或聚合信息(如总数或平均值)的情况。
数据导入方式
Doris 的导入主要涉及数据源、数据格式、导入方式、错误数据处理、数据转换�、事务多个方面。您可以在如下表格中快速浏览各导入方式适合的场景和支持的文件格式。
| 导入方式 | 使用场景 | 支持的文件格式 | 单次导入数据量 | 导入模式 |
|---|---|---|---|---|
| Stream Load | 导入本地文件或者应用程序写入 | csv、json、parquet、orc | 小于10GB | 同步 |
| Broker Load | 从对象存储、HDFS等导入 | csv、json、parquet、orc | 数十GB到数百 GB | 异步 |
| INSERT INTO VALUES | 通过JDBC等接口导入 | SQL | 简单测试用 | 同步 |
| INSERT INTO SELECT | 可以导入外部表或者对象存储、HDFS中的文件 | SQL | 根据内存大小而定 | 同步 |
| Routine Load | 从kakfa实时导入 | csv、json | 微批导入 MB 到 GB | 异步 |
| MySQL Load | 从本地数据导入 | csv | 小于10GB | 同步 |
| Group Commit | 高频小批量导入 | 根据使用的导入方式而定 | 微批导入KB | - |
更多Doris 细节可以查看官网,官网比较详细 https://doris.apache.org/docs/gettingStarted/what-is-new/
优化方案
优化表 Schema 设计
## 案例 1:表引擎选择
Doris 支持 Duplicate、Unique、Aggregate 三种表模型。其中,Unique 又可以进一步分为 Merge-On-Read(MOR)和 Merge-On-Write(MOW)两种。
这几种表模型的查询性能,由好到差依次为:Duplicate > MOW > MOR == Aggregate。因此,通常情况下,如果没有特殊需求,推荐使用 Duplicate 表,以获得更好的查询性能。
当业务无数据更新需求,但对查询性能有较高要求时,推荐使用 [Duplicate 表]。