Hudi
Hudi 是 Apache 开源的数据湖框架,支持数据的增量更新和流式处理。Hudi 面试题的考察重点包括 Hudi 的表类型(COW、MOR)、增量数据的处理机制、Hudi 的索引与数据同步、数据的快速插入与更新、与 Hive 和 Spark 的集成、查询优化策略、以及如何在数据湖场景中实现高效的数据管理。
什么是 Apache Hudi?它的主要功能是什么?
Apache Hudi 是一款用于管理大规模数据集的开源数据管理框架。它的名称 “Hudi” 是 "Hadoop Upserts and Incrementals" 的缩写。Hudi 的主要功能是帮助用户更高效地管理和处理大数据集,特别是当数据具有高频更新需求时。Hudi 可以在数据湖(主要是基于 Hadoop HDFS 或者云��存储如 AWS S3、Google Cloud Storage 等)的基础上更有效地进行数据增量更新、批处理与流处理融合。
Hudi 主要具备以下几个功能:
1)数据更新(Upserts):Hudi 提供原生的支持允许用户对数据进行更新而不是只追加。
2)增量处理(Incremental Processing):Hudi 允许用户进行基于增量数据的处理,从而减少数据处理时间和资源消耗。
3)数据版本管理(Versioning):通过时间线管理和数据快照机制,Hudi 使得数据恢复和回滚变得简单。
4)数据压缩和索引(Compaction and Indexing):Hudi 实现了数据压缩和索引机制,提高了查询性能和存储效率。
扩展知识
让我详细讲讲这些功能以及 Apache Hudi 的优势和使用场景。
1)数据更新(Upserts): 传统的 Hadoop 或者离线批处理系统对于数据处理大多数是追加操作,这是因为对大数据集进行更新操作往往成本极高。Hudi 通过结合写时合并(Write-time Merging)和读时合并(Read-time Merging)的技术提供了更高效的数据更新机制。
2)增量处理(Incremental Processing): 在大数据处理系统中,经常会遇到需要处理新的数据增量的需求。Hudi 提供了一种方式,只处理新增加或修改的数据,而不需要重新处理整个数据集,可以显著提高处理效率。Hudi 基于时间线管理(Timeline Service),用户可以方便地提取新增加的数据。
3)数据版本管理(Versioning): 每次的数据修改(更新、删除、插入)都会生成一个新的数据版本,Hudi 通过时间线管理这些版本,用户可以基于不同的时间快照进行数据查询或恢复,从而实现数据回滚功能。这个特��性对于数据分析和审计尤其有用。
4)数据压缩和索引(Compaction and Indexing): 为了提高 IO 性能和存储效率,Hudi 提供了数据压缩机制,可以选择在写入数据时进行小文件合并。索引功能则可以加速查询,帮助用户快速查找到所需的数据。
使用场景:
- 需要频繁更新的大数据集,如用户日志数据、交易数据。
- 需要增量处理的实时流数据处理场景。
- 数据质量和一致性要求高的数据湖场景。
与其他大数据工具的对比:
- 与 Apache Hive 和 Apache Parquet 相比,Hudi 提供了更好的数据更新能力和增量处理特性。
- 与 Apache Kafka 和 Apache Flink 结合,Hudi 可以处理流数据并将其高效地管理在 Hadoop 数据湖中。
Hudi 核心概念
时间轴(TimeLine)
Hudi 的核心是维护一个 timeline 日志,该日志记录了在不同 instants 时间对表执行的所有操作,有助于提供表的即时视图,同时还有效地支持按到达顺序检索数据。Hudi Instant 由以下组件组成
Instant action:对表执行的操作类型Instant time:即时时间通常是一个时间戳(例如:20190117010349),它按操作开始时间的顺序单调增加。state:瞬间的当前状态
Hudi保证在时间线上执行的操作是原子的,并且基于即时时间的时�间线一致。原子性是通过依赖对底层存储的原子 put 来实现的,以在时间线中的各种状态之间移动写入操作。这是在底层 DFS 上实现的(在 S3/Cloud Storage 的情况下,通过原子 PUT 操作),并且可以通过 Hudi 时间线 <instant>.<action>.<state> 中模式的文件进行观察。
Actions
COMMITS - 提交表示将一批记录原子写入表中。
CLEANS - 后台活动,用于删除表中不再需要的旧版本文件。
DELTA_COMMIT - 增量提交是指将一批记录原子写入 MergeOnRead 类型表中,其中部分/全部数据可以只写入增量日志。
COMPACTION - 用于协调 Hudi 中差异数据结构的后台活动,例如:将更新从基于行的日志文件移动到列格式。在内部,压缩表现为时间线上的特殊提交
ROLLBACK - 表示提交/增量提交未成功并回滚,删除了在此类写入过程中产生的任何部分文件。
SAVEPOINT - 将某些文件组标记为 “已保存”,以便 Cleaner 不会删除它们。它有助于在发生灾难/数据恢复情况时将表还原到时间线上的某个点。
States
任何给定的 moment 都可以处于以下状态之一
REQUESTED- 表示已安排操作,但尚未启动INFLIGHT- 表示当前正在执行操作COMPLETED- 表示完成时间轴上的操作
所有处于 requested/inflight 状态的操作都作为名为 .. 的文件存储在活动时间线中<begin_instant_time><action_type>。<requested|inflight>。已完成的操作与表示操作完成时间的时间一起存储在名为 <begin_instant_time><completion_instant_time>.<action_type>.**
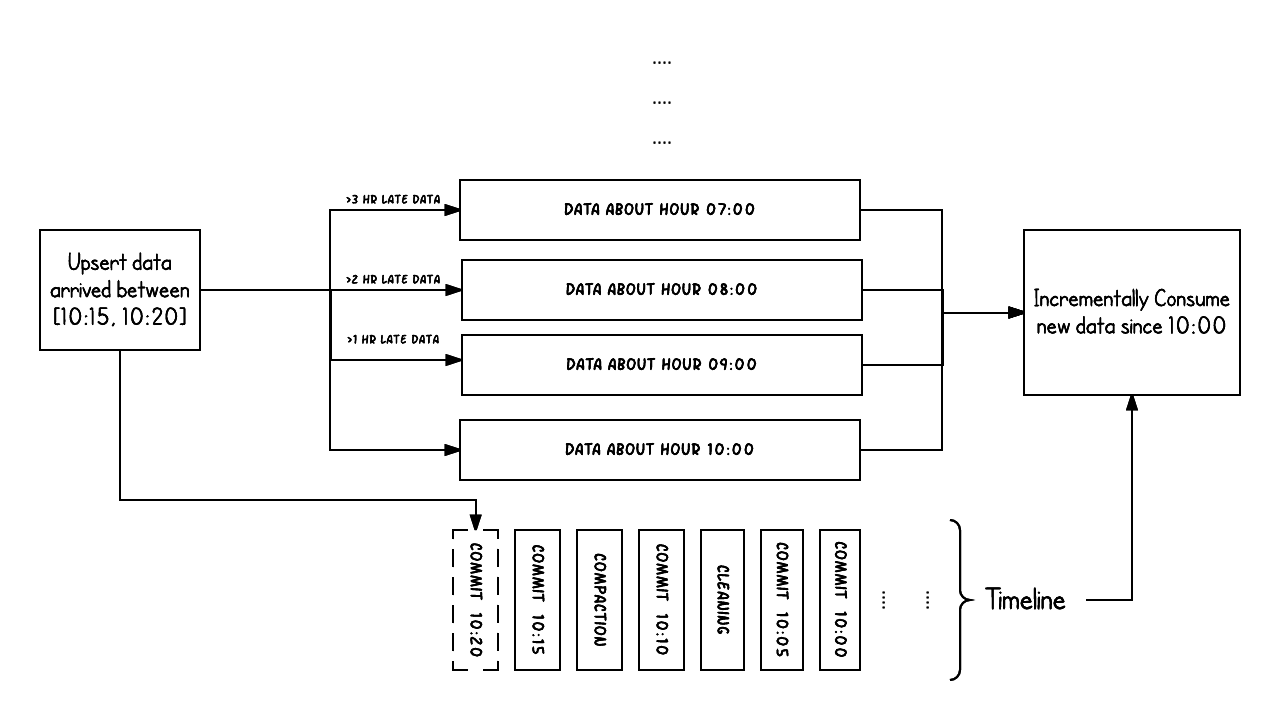
上面的示例显示了 Hudi 表在 10:00 到 10:20 之间发生的更新插入,大约每 5 分钟一次,将提交元数据留在 Hudi 时间线上,以及其他后台清理/压缩。需要注意的一个关键问题是,提交时间表示数据 arrival time 的时间 (10:20AM),而实际数据组织反映的是数据的预期时间 event time (从 07:00 开始的每小时存储桶)。在考虑延迟和数据完整性之间的权衡时,这是两个关键概念。
Arrival time: 数据到达 Hudi 的时间,commit time。
Event time: record 中记录的时间
文件布局(File Layout)
-
Hudi 将数据表组织到分布式文件系统上基本路径下的目录结构中
-
表被分解为多个分区
-
在每个分区中,文件被组织到文件组中,由文件 ID 唯一标识
-
每个文件组都包含多个文件切片
-
每个切片都包含在某个提交/压缩即时时间生成的基本文件 (.parquet/.orc)(由配置 - hoodie.table.base.file.format 定义),以及一组日志文件 (.log.),其中包含自生成基本文件以来对基本文件的插入/更新。
/data/hudi_trips/ <== Base Path
├── .hoodie/ <== Meta Path
| └── hoodie.properties <== Table Configs
│ └── metadata/ <== Table Metadata
├── americas/
│ ├── brazil/
│ │ └── sao_paulo/ <== Partition Path
│ │ ├── <data_files>
│ └── united_states/
│ └── san_francisco/
│ ├── <data_files>
└── asia/
└── india/
└── chennai/
├── <data_files>
Hudi 采用多版本并发控制 (MVCC),其中压缩操作合并日志和基本文件以生成新的文件切片,而清理操作删除未使用/较旧的文件切片以回收文件系统上的空间。
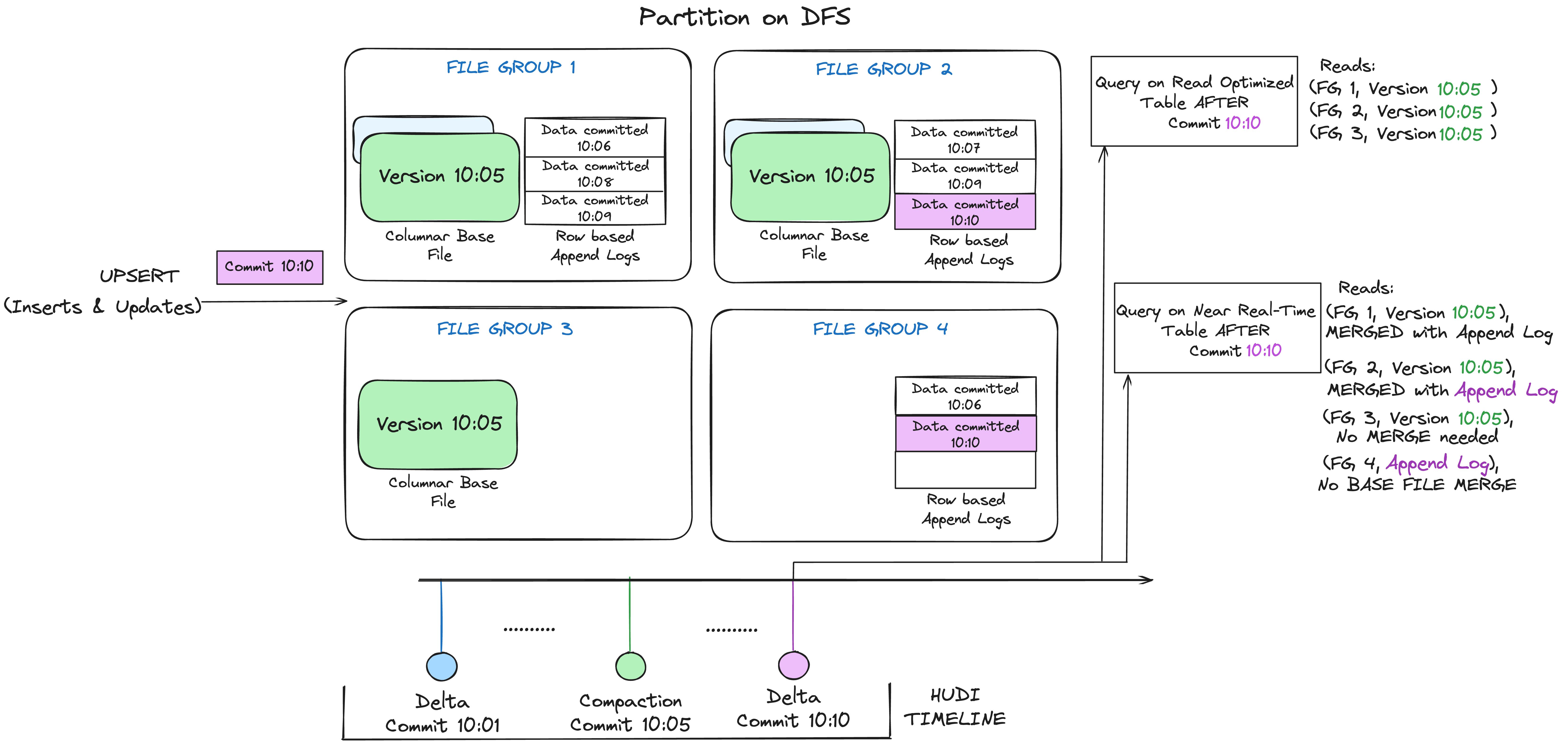
compaction操作:合并日志和基本文件以产生新的文件片
clean操作:清除不使用的/旧的文件片以回收文件系统上的空间
索引(Index)
Hudi通过索引机制提供高效的upserts,具体是将给定的hoodie key(record key + partition path)与文件id(文件组)建立唯一映射。这种映射关系,数据第一次写入文件后保持不变,所以,一个 FileGroup 包含了一批 record 的所有版本记录。Index 用于区分消息是 INSERT 还是 UPDATE。
Indexing 索引
目前,Hudi 支持以下索引类型。在 Spark 引擎上默认为 SIMPLE,在 Flink 和 Java 引擎上默认为 INMEMORY。
-
BLOOM:使用从记录键生成的 bloom 筛选条件,并可选择根据记录键的范围进一步缩小候选文件的范围。它要求 key 是分区级别的唯一,以便它可以正常运行。
-
GLOBAL_BLOOM:利用从记录键创建的 bloom 过滤器,还可以通过使用记录键的范围来优化候选文件的选择。它要求 keys 是表/全局级别的唯一,以便它可以正常运行。
-
SIMPLE(Spark 引擎的默认值):这是 Spark 引擎的标准索引类型。它执行传入记录与从磁盘上存储的表中检索的键的高效联接。它要求 key 是分区级别的唯一,以便它可以正常运行。
-
GLOBAL_SIMPLE:根据从存储表中提取的键执行传入记录的精简联接。它要求 keys 是表/全局级别的唯一,以便它可以正常运行。
-
HBASE:通过 Apache HBase 中的外部表管理索引映射。
-
INMEMORY(Flink 和 Java 的默认值):使用 Spark 和 Java 引擎中的内存哈希图以及 Flink 中的 Flink 内存状态进行索引。
-
BUCKET:利用存储桶哈希来识别包含记录的文件组,这在大规模上被证明特别有利。要选择存储桶引擎的类型(即创建存储桶的方法),请使用
hoodie.index.bucket.engineconfiguration 选项。SIMPLE(default):此索引为每个分区中的文件组使用固定数量的存储桶,这些文件组无法减小或增加大小。它适用于 COW 和 MOR 表。由于存储桶的数量不可更改,并且每个存储桶的设计原则是将每个存储桶映射到单个文件组,因此这种索引方法可能不适用于具有显著数据倾斜的分区。CONSISTENT_HASHING:此索引可容纳动态数量的存储桶,并具有调整存储桶大小的功能,以确保每个存储桶的大小都适当。这允许动态调整具有大量数据的分区的大小,从而解决了这些分区中的数据倾斜问题。因此,分区可以有多个大小合理的存储桶,这与 SIMPLE 存储桶引擎类型中每个分区的固定存储桶计数不同。此功能与 MOR 表完全兼容。 -
RECORD_INDEX:此索引将记录键保存到 HUDI 元数据表中的位置映射。它充当全局索引,要求键在表内的所有分区中是唯一的。为了适应非常高的规模,它利用了分片。记录索引经过专门优化,可实现快速更新插入。此外,在读取数据时,该索引经过精心设计,允许快速查找点,从而显着加快数据检索过程。
-
自带实现:您可以扩展此公共 API 以实现自定义索引。
全局索引和非全局索引
全局索引:全局索引在表的所有分区中强制执行键的唯一性,即保证给定记录键的表中只存在一条记录。全局索引提供了更强的保证,但更新/删除成本仍会随着 size of the table O(size of table) 而增加,因为记录可能属于 storage 中的任何分区。在非全局索引的情况下,查找仅涉及来自传入记录的匹配分区的文件组,因此它不受表总大小的影响。这些全局索引(GLOBAL_SIMPLE 或 GLOBAL_BLOOM)对于大小合适的表可能是可以接受的,但对于大型表,新添加的索引(0.14.0)称为记录级索引 (RLI),与其他全局索引(GLOBAL_SIMPLE 或 GLOBAL_BLOOM)或 Hbase 相比,可以提供相当不错的索引查找性能,并且还避免了维护外部系统的运营开销。
Non Global index:另一方面,默认索引实现仅在特定分区内强制执行此约束。正如人们可以想象的那样,非全局索引依赖于写入器在更新/删除期间为给定的记录键提供相同的一致分区路径,但可以提供更好的性能,因为索引查找操作会随着写入卷的 O(number of records updated/deleted) 生成和扩展而很好地扩展。
表类型(Table Types)
| 表类型 | 支持的 Query 类型 |
|---|---|
| Copy On Write 写时复制 | Snapshot Queries 快照查询 Incremental Queries 增量查询 Incremental Queries (CDC) 增量查询 (CDC) Time Travel 时间旅行 |
| Merge On Read 读取时合并 | Snapshot Queries 快照查询 Incremental Queries 增量查询 Read Optimized Queries 读取优化查询 Time Travel 时间旅行 |
两种表类型之间的对比
| Trade-off | CopyOnWrite (复制写入) | MergeOnRead (合并读取) |
|---|---|---|
| 数据延迟 | 高 | 低 |
| 查询延迟 | 低 | 高 |
| 更新成本 (I/O) | 高 | 低 |
| Parquet 文件大小 | 更小 | 更大 |
| 写入放大 | 高 | 较低(取决于压缩策略) |
查询类型(Query Types)
-
Snapshot Queries 快照查询 :查询查看给定提交或压缩操作时表的最新快照。在读取表上合并的情况下,它通过动态合并最新文件切片的 base 和 delta 文件来公开近乎实时的数据(几分钟)。对于写入时复制表,它为现有 Parquet 表提供了直接替换,同时提供 upsert/delete 和其他写入端功能。
-
Incremental Queries 增量查询:查询仅查看自给定提交/压缩以来写入表的新数据。这有效地提供了更改流以启用增量数据管道。默认情况下,这会生成自时间线中给定时间点以来更改的最新快照。
- 增量查询 (CDC) :这些是增量查询的一个子类型,其中查询查看自给定提交/压缩以来所有更改的数据,而不是更改数据的最新状态。这支持完整的 cdc 样式查询使用案例,允许查看更改的前后图像以及导致更改的操作。
-
Read Optimized Queries 读取优化查询:查询可查看截至给定提交/压缩操作的表的最新快照。在最新的文件切片中仅公开基本/列式文件,并保证与非 hudi 列式表相比具有相同的列式查询性能。
-
Time Travel Queries 时间旅行:查询截至时间轴中给定时间戳的表快照。
Snapshot 和 Read Optimized 查询类型对比
| Trade-off | Snapshot 快照 | Read Optimized 读取优化 |
|---|---|---|
| 数据延迟 | 更低 | 更高 |
| 查询延迟 | Higher (merge base / columnar file + row based delta / log files) 更高(合并基础/列式文件 + 基于行的增量/日志文件) | Lower (raw base / columnar file performance) 较低(原始基准/列式文件性能) |
引用:https://hudi.apache.org/tech-specs/#file-layout-hierarchy