CDH 6.3.2 服务安装
规划
我们在安装服务之前,要对当前的硬件资源进行一次规划,以便后续的服务安装。
- 集群管理:主要就是 cm 服务,这个服务是必须的,用于集群的管理。
- 管理节点:主要安装 zookeeper、hdfs namenode 、Yarn ResourceManager、Hive Metastore、Hue 等不吃内存的服务。
- 数据/计算节点:存放数据和计算的节点,主要就是硬盘大,内存大,CPU 多的节点,安装 hdfs datanode、Yarn NodeManager、Impala Daemon 等
对硬件的规划要有前瞻性,切勿盲目分配,导致资源浪费。哪怕只有 3 台机器,也要将服务错开部署,避免机器资源的不平衡,造成浪费甚至导致无法计算。
提�醒
请按照以下顺序安装,这样避免依赖过程缺少依赖组件。我们在安装服务的时候,会对服务进行一些简单的配置,这些配置最好是在安装时操作,等其他组件安装完成再进行调整,容易出现问题。
1.zookeeper 安装
Apache ZooKeeper 是用于维护和同步配置数据的集中服务 安装策略 2n+1
| 服务器数量 | zk节点 |
|---|---|
| 10 | 3 |
| 20 | 5 |
| 100 | 11 |
安装选择:管理节点
台数并不是越多越好, 太多选举时间过长影响性能。
2.HDFS 安装
| 角色名称 | 功能 | 数量 | 节点选择 |
|---|---|---|---|
| NameNode | 元数据管理 | 1 | 管理节点 |
| SecondNameNode | 备用节点 | 1 | 管理节点 |
| DataNode | 数据节点 | 若干 | 计算节点/存储节点 |
| JournalNode | 存放EditLog | 3 | 管理节点 |
JournalNode 是在配置高可用时选择
NameNode 一般在主节点上,初始化安装的时候没有高可用,所以有 SecondaryNameNode 的作为一个备份,NameNode 它会将它拆分后进行分布式存储,其中的数据是分散在各个 DataNode 节点,且默认都会有 3 个副本,防止其中一台机器宕机使得数据缺失,所以一般集群有几台机器就分配到几台机器上,balancer 一般与 NameNode 搭建在一起
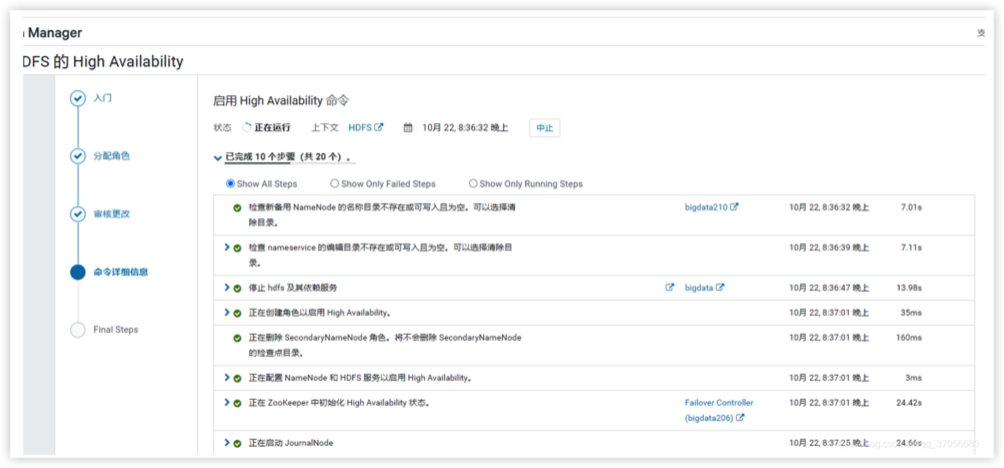
高可用配置 HDFS -> 操作 -> 开启 High Availability
1.选择 HDFS
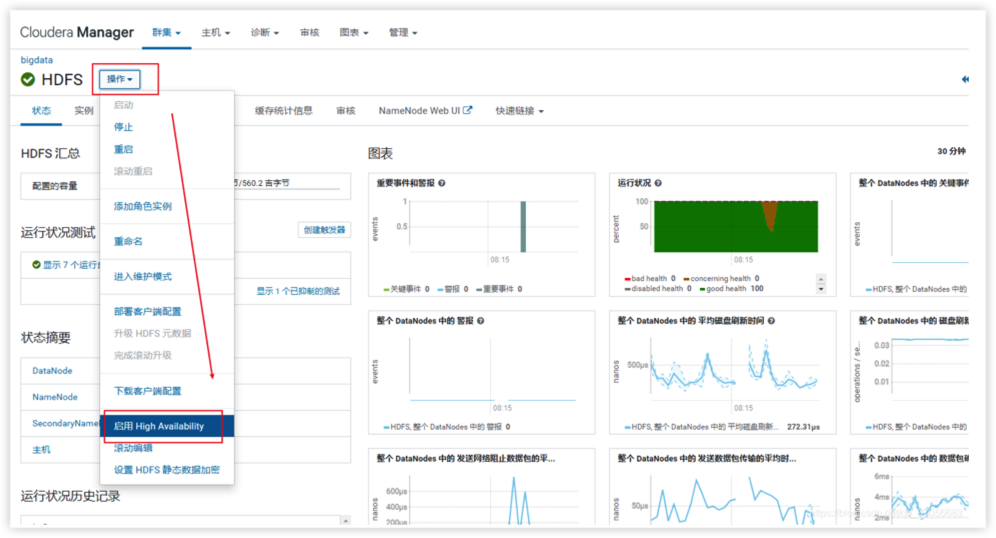
2.启用 High Availability
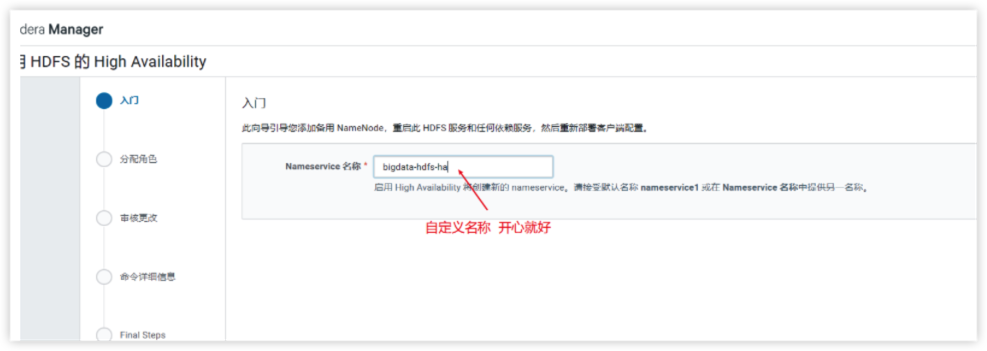
3.对Namenode服务设置名称(用默认 nameservice1 就可以)
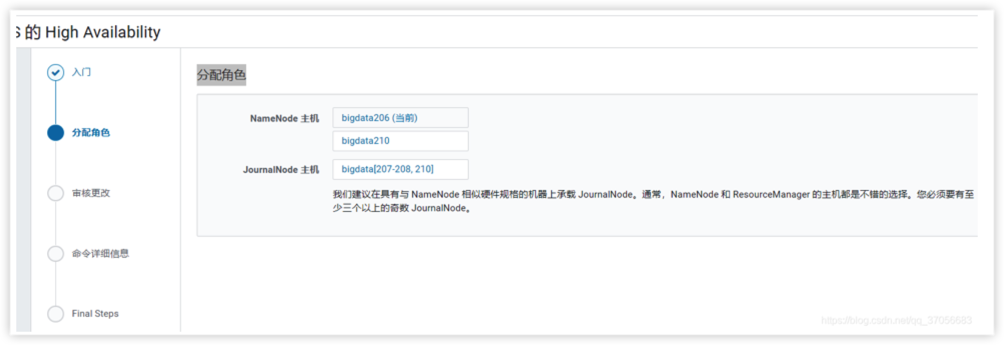
4.分配角色(分配给管理节点即可)
5.编辑数据存放目录(/data/dfs/jn)
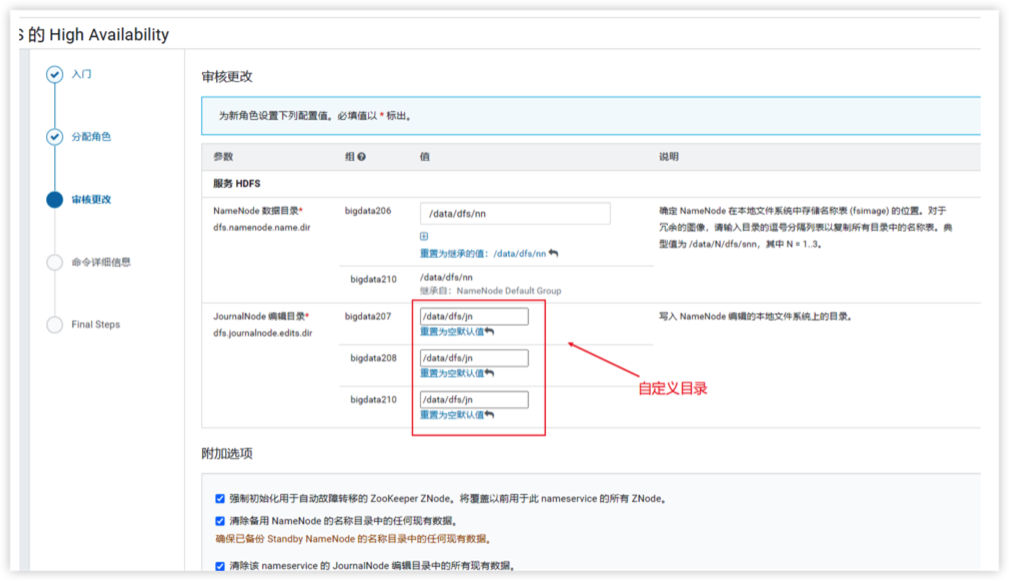
6.确认启用
如果已经安装了Hive,开启高可用后需要刷新Hive元数据
Hive -> 操作 -> 更新 Hive Metastore NameNode(需要先关闭Hive)
否则会造成数��据无法访问
3.Yarn 安装
| 角色 | 节点 |
|---|---|
| RM(ResourceManager) 主 | 管理节点 |
| RM(ResourceManager) 备 | 管理节点 |
| NodeManager | 计算节点 |
| JobHistory Server | 管理节点 |
| Gateway | 计算节点 |
❗️RM(ResourceManager) 主 尽量避免与 HDFS NameNode 主机点配置在一台机器上
ResourceManager负责集群中所有资源的统一管理和分配,它接收来自各个NodeManager的资源汇报信息
NodeManager 计算节点
JobHistory Server job运行历史记录
Gateway集群可以作为一个独立的作业提交点
yarn.nodemanager.local-dirs 选择大的磁盘空间,默认是 / 下
4.Hive 安装
Hive 是一种数据仓库系统,提供名为 HiveQL 的 SQL 类语言
| 角色 | 节点 |
|---|---|
| Hive Metastore Server | 管理节点 |
| Hive server2 | 管理节点 |
Hive Metastore Server 元数据管理
HiveServer2(HS2) 是一种能使客户端执行Hive查询的服务
HiveServer2 最好做HA,但节点的连接数默认是 100
5.HUE
Hue 是与包括 Apache Hadoop 的 Cloudera Distribution 配合使用的图形用户界面(需要 HDFS、MapReduce 和 Hive)�。
| 角色 | 节点 |
|---|---|
| Hue Server | 管理节点 |
| Load Balancer | 管理节点 |
| Load Balancer | 管理节点 |
6.Impala
Impala 为存储在 HDFS 和 HBase 中的数据提供了一个实时 SQL 查询接口。Impala 需要 Hive 服务,并与 Hue 共享 Hive Metastore。
| 角色 | 节点 |
|---|---|
| Impala Catalog Server | 管理节点 |
| Impala StateStore | 管理节点 |
| Impala Daemon | 计算节点 |
Impala Catalog Server 负责impala元数据管理
Impala StateStore 并周期性检查impala进程状态,并同步发给各个impalaD
impala deamon:impala D和hdfs dataNode进程协同服务,执行用户提交的查询。
7.Spark
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎
| 角色 | 节点 |
|---|---|
| History Server | 管理节点 |
| Gateway | 计算节点 |
8.Impala
Hue 搜索 Impala 服务,选择 impala