Flink
简单介绍一下 Flink
Flink 是一个框架和分布式处理引擎,用于对无界和有界数据流进行有状态计算。并且 Flink 提供了数据分布、容错机制以及资源管理等核心功能。Flink提供了诸多高抽象层的API以便用户编写分布式任务:
- DataSet API, 对静态数据进行批处理操作,将静态数据抽象成分布式的数据集,用户可以方便地使用Flink提供的各种操作符对分布式数据集进行处理,支持Java、Scala和Python。
- DataStream API,对数据流进行流处理操作,将流式的数据抽象成分布式的数据流,用户可以方便地对分布式数据流进行各种操作,支持Java和Scala。
- Table API,对结构化数据进行查询操作,将结构化数据抽象成关系表,并通过类SQL的DSL对关系表进行各种查询操作,支持Java和Scala。
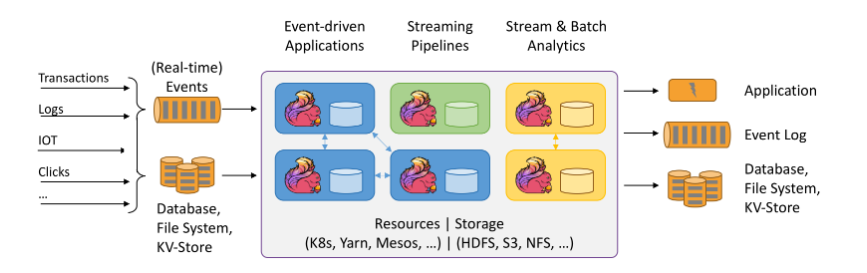
此外,Flink 还针对特定的应用领域提供了领域库,例如: Flink ML,Flink 的机器学习库,提供了机器学习Pipelines API并实现了多种机器学习算法。 Gelly,Flink 的图计算库,提供了图计算的相关API及多种图计算算法实现。
Flink编程模型是什么?
1)Flink分层模型
Flink底层通过封装和抽象,提供四级分层编程模型,以此支撑业务开发实时和批处理程序。
结合示意图,我们由下而上进行介绍。

Runtime层:Flink程序的最底层入口。提供基础的核心接口完成流、状态、事件、时间等复杂操作,功能灵活但使用成本较高,一般面向源码研发人员。DataStream/Dataset API层:这一层主要面向开发者。基于Runtime层抽象为两类API,其中DataStream API处理实时流程序;Dataset API处理批数据程序。Table API:统一DataStream/DataSet API,抽象成带有Schema信息的表结构API。通过Table操作和注册表完成数据计算,支持与DataStream/Dataset相互转换。SQL:面向数据分析和开发人员,抽象为SQL操作,降低开发门槛和平台化。
2)Flink计算模型
Flink的计算模型和Spark的模型有些类似。包含输入端(source)、转换(Transform)、输出端(sink)。
source端:Flink程序的输入端,支持多个数据源对接Transformation:Flink程序的转换过程,实现DataStream/Dataset的计算和转换sink端: Flink的输出端,支持内部和外部输出源

Flink 工作原理
Flink底层执行分为客户端(Client)、Job管理器(JobManager)、任务执行器(TaskManager)三种角色组件。其中Client负责Job提交;JobManager负责协调Job执行和Task任务分配;TaskManager负责Task任务执行。
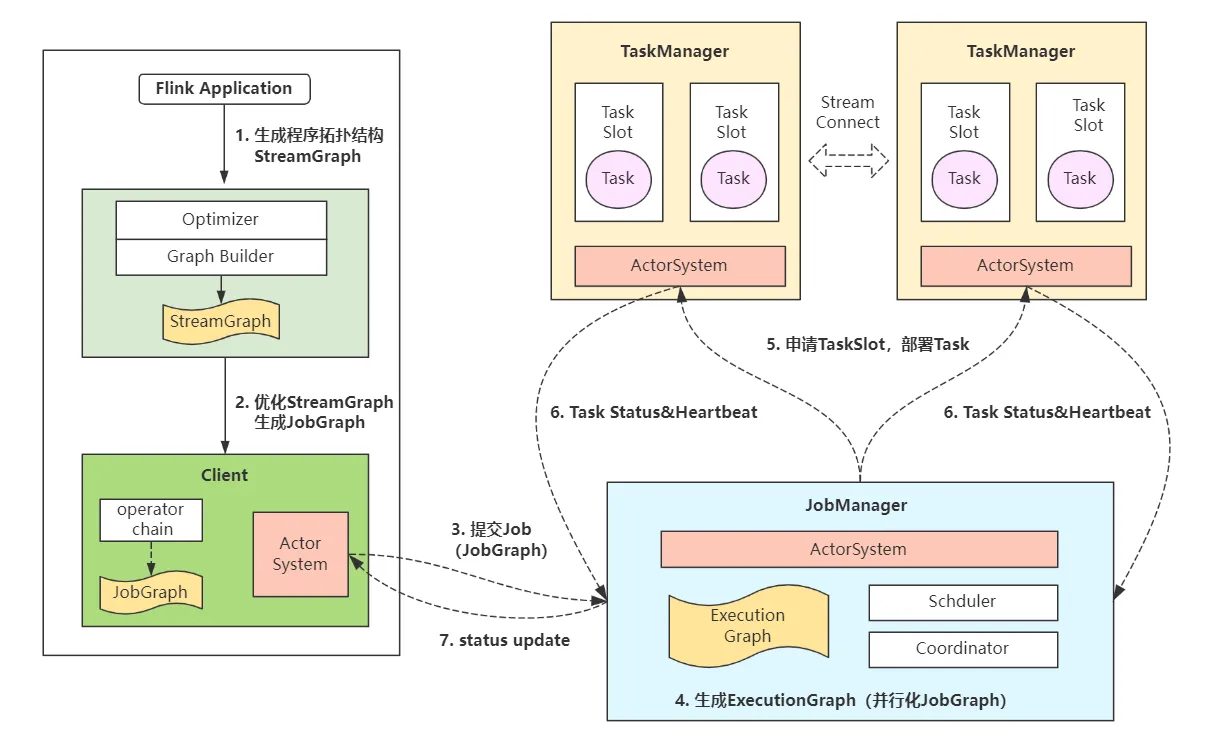
Flink常见执行流程如下(调度器不同会有所区别):
- 1)用户提交流程序Application。
- 2)Flink
解析StreamGraph。Optimizer和Builder模块解析程序代码,生成初始StreamGraph并提交至Client。 - 3)Client
生成JobGraph。上述StreamGraph由一系列operator chain构成,在client中会被转换为JobGraph,即优化多个chain为一个节点,最终提交到JobManager。 - 4)JobManager
调度Job。JobManager和Client的ActorSystem保持通信,并生成ExecutionGraph(并行化JobGraph)。随后Schduler和Coordinator模块协调并调度Jobz执行。 - 5)TaskManager
部署Task。TaskManager和JobManager的ActorSystem保持通信,接受job调度计划并在内部划分TaskSlot部署执行Task任务。 - 6)Task
执行。Task执行期间,JobManager、TaskManager和Client之间保持通信,回传任务状态和心跳信息,监控任务执行。
公司怎么提交Flink实时任务的?
顾名思义,这里涉及Flink的部署模式内容。一般Flink部署模式除了Standalone之外,最常见的为Flink on Yarn和Flink on K8s模式,其中Flink on Yarn模式在企业中应用最广。
Flink on Yarn模式细分由可以分为Flink session、Flink per-job和Flink application模式
1)Flink session模式
Flink Session模式会首先启动一个集群,按照配置约定,集群中包含一定数量的JobManager和TaskManager。后面所有提交的Flink Job均共享该集群内的JobManager和TaskManager,即所有的 Flink Job 竞争相同资源。
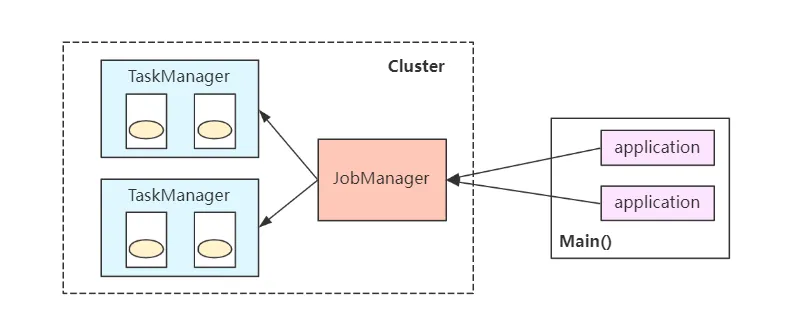
这样做的好处是节省作业提交资源开销(集群已存在),减少资源和线程切换工作。但是所有作业共享一个JobManager,导致JobManager压力激增,同时一旦某Job发生故障时会影响到其他作业(中断或重启)。一般仅适用于短周期、小容量作业。
Flink-session模式的作业提交流程:
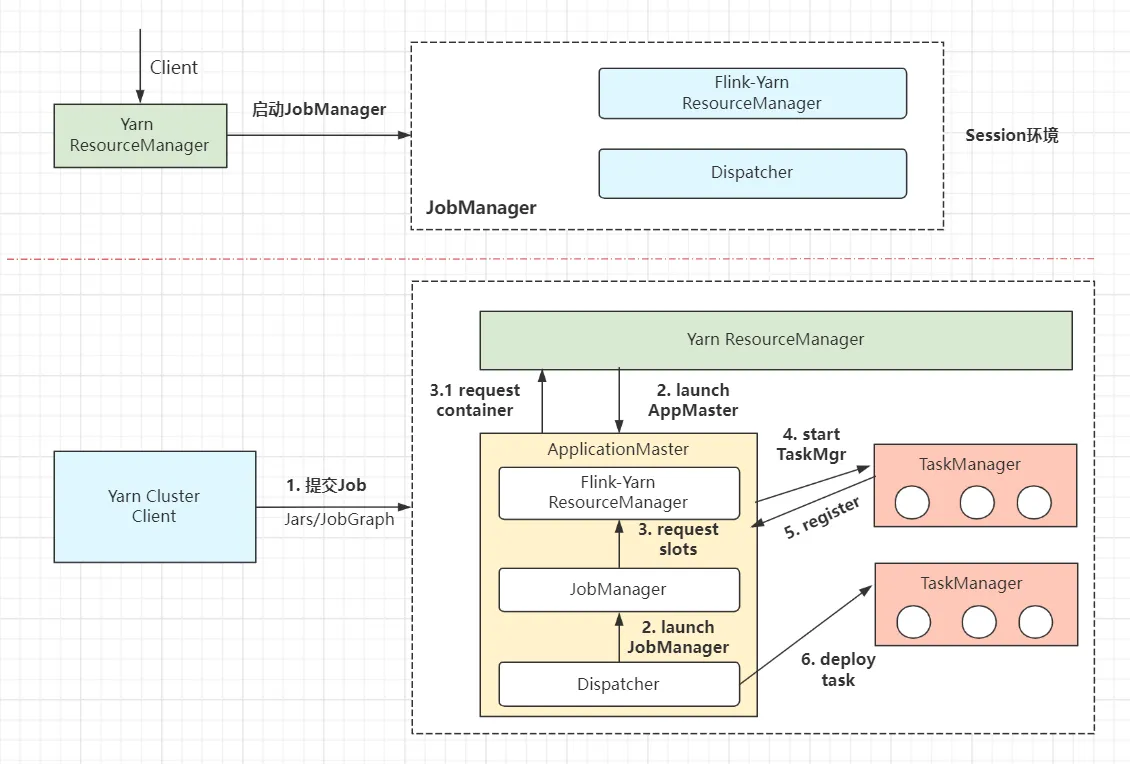
- (1)整体流程分为两部分:yarn-session 集群启动、Job提交。
- (2)
yarn-session集群启动。请求YarnRM启动JobManager,随后JobManager内部启动Dispatcher和Flink-yarnRM进程,等待后续Job提交。 - (3)
Client提交Job。Client连接Dispatcher开始提交Job,包含jars和解析过的JobGraph拓扑数据结构。 - (4)
Dispatcher启动JobMaster,JobMaster向Yarn RM请求slots资源。 - (5)Flink-Yarn RM 向 Yarn RM 请求
Container资源,准备启动TaskManager。 - (6)Yarn启动
TaskManager进程。TaskManager同时向Flink RM反向注册(自身可用的slots槽数) - (7)
TaskManager为新的作业提供slots,与JobMaster通信。 - (8)
JobMaster将执行的任务分发给TaskManager,开始部署执行任务
2)Flink Per-job模式
Flink Per-job模式为每个提交的作业启动集群,各集群间相互独立,并在各自作业完成后销毁,最大限度保障资源隔离。每个Job均衡分发自身的JobManager,单独进行job的调度和执行。
虽然该模式提供了资源隔离,但是每个job均维护一个集群,启动、销毁以及资源请求消耗时间长,因此比较适用于长时间的任务执行(批处理任务)。
Per-job模式在Flink 1.15中弃用,目前推荐使用applicaiton模式。
Flink 中的 Time 有哪几种
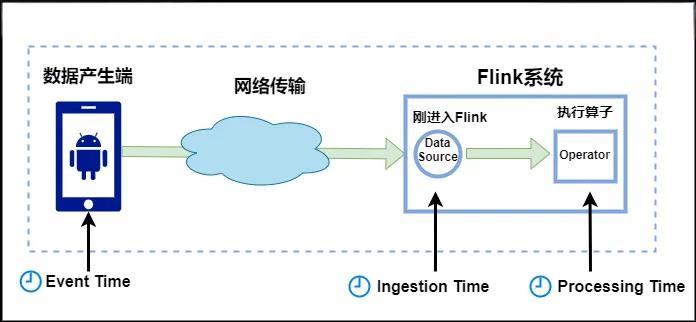
-
Event Time:是事件创建的时间。它通常由事件中的时间戳描述,例如采集的日志数据中,每一条日志都会记录自己的生成时间,Flink通过时间戳分配器访问事件时间戳。
-
Ingestion Time:是数据进入Flink的时间。
-
Processing Time:是每一个执行基于时间操作的算子的本地系统时间,与机器相关,默认的时间属性就是Processing Time。
对于业务来说,要统计1min内的故障日志个数,哪个时间是最有意义的?—— eventTime,因为我们要根据日志的生成时间进行统计。
Flink 窗口?
Flink 的窗口(Window)是处理无界数据流的核心机制,用于将无限流切割成有限的 “窗口” 进行分组聚合。根据窗口触发机制和时间特性,主要分为以下几类:
时间窗口 - 基于时间的窗口(处理时间和事件时间)
- 滚动时间窗口(Tumbling Time Window):固定大小的窗口,不重叠
- 滑动时间窗口(Sliding Time Window): 固定大小的窗口,可重叠
- 会话窗口(Session Window): 由活动会话定义,非固定大小
计数窗口 - 基于元素计数的窗口
- 滚动计数窗口:每收集 N 个元素处理一次
- 滑动计数窗口:每收集 M 个元素后,对最近的 N 个元素处理一次
全局窗口 - 一种特殊的窗口类型,它会将相同键(Key)的所有数据都分配到同一个窗口中,不基于时间或元素数量进行划分。全局窗口本身不会主动触发计算,需要配合自定义的 触发器(Trigger) 来决定何时对窗口内的数据进行处理
Flink 的容错机制(checkpoint)
Checkpoint机制是Flink可靠性的基石,可以保证Flink集群在某个算子因为某些原因(如 异常退出)出现故障时,能够将整个应用流图的状态恢复到故障之前的某一状态,保证应用流图状态的一致性。Flink的Checkpoint机制原理来自“Chandy-Lamport algorithm”算法。
每个需要Checkpoint的应用在启动时,Flink的JobManager为其创建一个 CheckpointCoordinator(检查点协调器),CheckpointCoordinator全权负责本应用的快照制作。
CheckpointCoordinator(检查点协调器),CheckpointCoordinator全权负责本应用的快照制作。
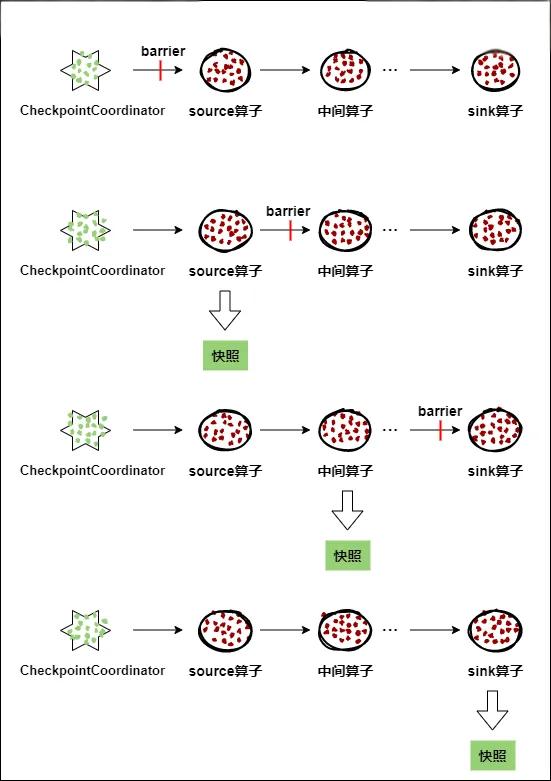
- CheckpointCoordinator(检查点协调器) 周期性的向该流应用的所有source算子发送 barrier(屏障)。
- 当某个source算子收到一个barrier时,便暂停数据处理过程,然后将自己的当前状态制作成快照,并保存到指定的持久化存储中,最后向CheckpointCoordinator报告自己快照制作情况,同时向自身所有下游算子广播该barrier,恢复数据处理
- 下游算子收到barrier之后,会暂停自己的数据处理过程,然后将自身的相关状态制作成快照,并保存到指定的持久化存储中,最后向CheckpointCoordinator报告自身快照情况,同时向自身所有下游算子广播该barrier,恢复数据处理。
- 每个算子按照步骤3不断制作快照并向下游广播,直到最后barrier传递到sink算子,快照制作完成。
- 当CheckpointCoordinator收到所有算子的报告之后,认为该周期的快照制作成功; 否则,如果在规定的时间内没有收到所有算子的报告,则认为本周期快照制作失败。
什么是 Savepoint ?
Savepoint 是 Flink 中一个很重要的机制,简单来说,它就是手动触发的一致性检查点,主要用于集群升级、版本迁移、暂停 / 重启作业等场景。
本质和作用 Savepoint 是基于 Flink 的检查点(Checkpoint)机制构建的,但和自动触发的检查点不同,它是手动触发的。
和 Checkpoint 的区别
-
触发方式:Checkpoint 是自动定期触发的(由配置决定),而 Savepoint 必须手动调用命令触发
-
用途:Checkpoint 主要用于故障恢复(比如机器宕机后自动从最近的 Checkpoint 恢复),而 Savepoint 更侧重人为控制的版本管理和作业调整。
-
Savepoint 在设计上更注重跨版本兼容性,比如作业代码修改后,通常需要从 Savepoint 恢复,而不是自动 Checkpoint(因为 Checkpoint 可能不兼容代码变更)
Savepoint 是 Flink 中手动触发的一致性检查点,主要用于人为控制的作业状态管理。比如在升级集群、修改代码或暂停作业时,通过 Savepoint 保存当前所有算子的状态和元数据到外部存储,后续可以从该点恢复作业,保证数据不丢失且状态一致。它和自动 Checkpoint 的区别在于触发方式和用途 ——Checkpoint 用于故障自动恢复,而 Savepoint 更侧重版本迁移和人工干预的场景,且兼容性更强
什么是状态后端
State Backend起到了持久化存储数据的重要功能。Flink将State Backend抽象成了一种插件,并提供了三种State Backend,每种State Backend对数据的保存和恢复方式略有不同
- MemoryStateBackend:
- 状态存储在 TaskManager 的 JVM 堆内存中,适用于开发和测试。
- 每个 checkpoint 的状态数据会发送到 JobManager 并存储在堆内存中。
- 限制:状态大小受 TaskManager 内存限制,不适合生产环境。
- FsStateBackend:
- 状态在 TaskManager 内存中维护,checkpoint 时异步写入外部文件系统(如 HDFS)。
- 适用于大状态、长窗口或高可用场景。
- RocksDBStateBackend:
- 状态存储在本地 RocksDB 数据库(磁盘),内存中仅缓存部分数据。
- 支持增量 checkpoint,适合超大规模状态(TB 级)。
- 缺点:读写性能低于内存,但容量不受 JVM 堆限制。
Flink 状态有哪些?
Flink有两种基本类型的状态:托管状态(Managed State)和原生状态(Raw State)
| Managed State | Raw State | |
|---|---|---|
| 状态管理方式 | Flink Runtime托管,自动存储、自动恢复、自动伸缩 | 用户自己管理 |
| 状态数据结构 | Flink提供的常用数据结构,如ListState、MapState等 | 字节数组:byte[] |
| 使用场景 | 绝大多数Flink算子 | 用户自定义算子 |
对Managed State继续细分,它又有两种类型:Keyed State和Operator State
| Keyed State | Operator State | |
|---|---|---|
| 适用算子类型 | 只适用于KeyedStream上的算子 | 可以用于所有算子 |
| 状态分配 | 每个Key对应一个状态 | 一个算子子任务对应一个状态 |
| 创建和访问方式 | 重写Rich Function,通过里面的RuntimeContext访问 | 实现CheckpointedFunction等接口 |
| 横向扩展 | 状态随着Key自动在多个算子子任务上迁移 | 有多种状态重新分配的方式 |
| 支持的数据结构 | ValueState、ListState、MapState等 | ListState、BroadcastState等 |
参考 https://lulaoshi.info/flink/chapter-state-checkpoint/state.html#为什么要管理状态
什么是水位线?
水位线(Watermark)用来衡量事件时间进展的机制,用于处理乱序时间和迟到的数据。从本质上来说,水位线就是一种时间戳。要正确的处理乱序时间,通常使用“水位线机制+事件时间+窗口”来实现的。
水位线多采用 Event Time (事件时间),如果没有显示指定,则采用 Processing Time,但是无法处理乱序。
水位线可以被理解成_个延迟触发机制。可以设置水位线的延时时长为/’系统会先校验已经到达的数据中最大的事件时间—maxEventTime 然后验证事件时间小于“maxEventTime - t"的所有数据星否都已经到达’如果有窗口的停止时间等于‘maxEvenTime - t”,则这个窗口被触发执行。窗口的执行是由水位线触发的。
水位线的生成策略
- 单调递增策略:适用于数据严格有序的场景,水位线直接等于当前最大事件时间。
- 固定延迟策略:最常用,适用于可预估延迟的场景,水位线 = 最大事件时间 - 固定延迟(如 3 秒)。
- 自定义策略:当数据延迟不规则或需结合业务逻辑时使用,需实现
WatermarkGenerator接口,重写onEvent()和onPeriodicEmit()方法。
对于迟到数据是怎么处理的
Flink中 WaterMark 和 Window 机制解决了流式数据的乱序问题,对于因为延迟而顺序有误的数据,可以根据eventTime进行业务处理,对于延迟的数据Flink也有自己的解决办法,主要的办法是给定一个允许延迟的时间,在该时间范围内仍可以接受处理延迟数据:
-
设置允许延迟的时间是通过allowedLateness(lateness: Time)设置
-
保存延迟数据则是通过sideOutputLateData(outputTag: OutputTag[T])保存
-
获取延迟数据是通过DataStream.getSideOutput(tag: OutputTag[X])获取
Flink 资源管理中 Task Slot 的概念
在Flink中每个TaskManager是一个JVM的进程, 可以在不同的线程中执行一个或多个子任务。 为了控制一个worker能接收多少个task。worker通过task slot(任务槽)来进行控制(一个worker至少有一个task slot)。
Flink的重启策略
“Flink 的重启策略直接作用于 TaskManager 中的 Task 实例,控制它们在发生故障时的恢复行为。具体场景包括:
-
Task 执行失败(如代码异常)、TaskManager 崩溃(如节点故障)、资源不足(如 OOM)等。
-
重启策略可在作业代码、客户端命令或全局配置文件中设置,优先级依次降低。
-
重启策略需与 Checkpoint 配合使用 —— 前者决定是否重启,后者决定能否恢复状态。
-
固定延迟重启策略
- 失败后按固定时间间隔重启,达到最大重启次数后终止作业。
- 适用于偶发故障(如短暂的资源波动),希望自动恢复的场景。
- 失败率重启策略
- 在指定时间窗口内,若失败次数超过阈值则终止作业;否则自动重启。
- 适用于需要控制失败频率的场景(如系统存在持续性故障时避免无限重启)。
- 无重启策略
- 作业失败后直接终止,不进行任何重启。
- 适用于需要人工介入处理故障的场景(如批处理作业或敏感任务)。
Flink 是如何保证 Exactly-once 语义的
Flink 实现精确一次(Exactly-Once)语义涉及多个层面的设计和实现,包括内部处理、状态管理和与外部系统的交互。
- 内部状态管理的精确一次语义
- checkpoint 机制
- 基于 Chandy-Lamport 算法的分布式快照实现
- 周期性为整个应用应用程序创建一致性快照
- 失败时,所有算子回滚到最近完成的检查点状态
- 检查点对齐
- 确保算子再创建状态快照前处理完成所有属于当前检查点的数据
- 通过分界线(Barrier)标记检查点边界
- 多输入流情况下进行对齐,确保状态一致性
- 端到端精确一次性语义(Source -> Sink)
- Source 端的精确一次保证
- 可设置数据源位置(kafka offset)
- 故障回复是从上次检查点记录的位置重新开始
- Sink 端的精确一次保证
- 两阶段提交协议(Two-Phase Commit,2PC)
- 预提交阶段:Sink 将数据写入到外部系统但不提交
- 提交阶段:检查点成功完成后提交事务
- 终止阶段:建店失败时回滚事务
- 两阶段提交协议(Two-Phase Commit,2PC)
- 幂等写入(Idempotent Writes)
- 设计写入操作使其多次执行产生相同结果
- 例如使用唯一标识符,确保重复数据只更新一次
- Source 端的精确一次保证
- 与外部系统集成的精确一次保证
- Kafka 集成
- 读取:记录消费的偏移点
- 写入:利用 Kafka 事务,确保重复数据只更新一次
- 数据库集成
- 使用事务特性与检查点机制配合
- 支持 XA事务的数据库
- 使用 JDBC 连接器与两阶段提交
- 文件系统集成
- 使用文件系统的原子重命名操作
- 先写临时文件,检查点成功后重命名
- Kafka 集成
优化方向
- 调整 Checkpoint 间隔(��避免过短导致频繁快照)
- 启动异步快照
Flink 的反压
反压(Backpressure)是 Flink 处理数据流速率不匹配问题的机制,它确保当下游算子处理速度跟不上上游数据生成速度时,系统不会崩溃或丢失数据。
产生反压的原因
- 处理能力不平衡:下游算子处理弱于上游、数据倾斜致部分任务负载过重、复杂操作(如窗口聚合)计算开销大
- 资源瓶颈:CPU / 内存不足、网络带宽受限、数据库瓶颈
- 垃圾回收暂停:JVM GC 导致处理暂停、大内存状态增加 GC 压力
反压的检测方法
-
Flink Web UI 监控:红色 >50% 的样本处于阻塞,黄色 10%-50% 阻塞,绿色正常
-
监控指标:
taskmanager.network.buffer-pool.available-buffers可用网络缓冲区数量(持续下降可能提示反压)taskmanager.memory.managed.used:状态后端内存使用率(过高可能导致反压)operator.backpressure-time:算子处于反压状态的时间比例
- 堆分析:通过分析 TaskManager 的堆转储文件,定位内存占用大的对象(如未释放的缓冲区)
反压的优化策略
-
数据倾斜优化
- 预聚合:在 KeyBy 前进行局部聚合(如使用
aggregate而非sum) - 两阶段聚合
- ��第一阶段:添加随机前缀,并行计算局部结果
- 移除前缀,全局聚合局部结果
- 预聚合:在 KeyBy 前进行局部聚合(如使用
-
优化慢算子
- 异步 I/O:将同步外部调用(如数据库查询)改为异步(使用
AsyncFunction) - 状态清理:避免无限增长的状态(如设置窗口 TTL、定期清理历史数据)
- 算子链优化:通过
env.disableOperatorChaining()或startNewChain()控制算子链合并,减少数据传输开销。
- 异步 I/O:将同步外部调用(如数据库查询)改为异步(使用
-
资源调优
- 调整并行度:通过
setParallelism()或 Web UI 动态调整,确保上下游算子资源匹配 - 内存配置
- 增加网络缓冲区数量(
taskmanager.network.memory.fraction) - 为状态后端分配更多内存(如 RocksDB 的
state.backend.rocksdb.memory.managed) - 升级硬件:增加 TaskManager 节点、提升网络带宽或使用 SSD 存储状态
- 增加网络缓冲区数量(
- 调整并行度:通过
-
反压防护机制
- 背压感知调度:Flink 1.14+ 支持基于反压指标的自适应调度,自动调整资源分配
- 限流机制:
- 在 Source 端实现速率限制(如 Kafka Source 的
flink.partition-discovery.interval-millis)。 - 使用令牌桶算法限制数据流入速度。
- 在 Source 端实现速率限制(如 Kafka Source 的
-
反压与 Checkpoint 的关系
- 反压可能导致 Checkpoint 超时: 当算子处于反压状态时,Barrier 传播会延迟,导致 Checkpoint 无法在超时时间内完成。
- 优化建议:
- 增加 Checkpoint 超时时间(
env.getCheckpointConfig().setCheckpointTimeout(...))。 - 启用异步快照(RocksDBStateBackend 默认支持)。
- 调整 Checkpoint 间隔,避免与反压高峰期重叠。
- 增加 Checkpoint 超时时间(
Flink 怎么管理内存?
核心是 「堆外 + 分块 + 二进制」:
- 堆外内存:把大状态(比如窗口聚合结果)存到 JVM 堆外(类似 Redis 用内存但不归 JVM 管),用 RocksDB 做存储引擎,避免 GC 风暴。
- 内存分块:把内存切成固定大小的
MemorySegment(类似硬盘分区),网络传输和状态读写都直接操作这些块,减少对象创建。 - 二进制存储:数据不存成 Java 对象(比如
HashMap),而是直接以二进制形式存,省掉 3 倍以上的对象头开销。
Flink 的Transform 算子都有哪些?
Flink 提供了丰富的数据转换(Transformation)算子,用于处理数据流。主要的
转换算子包括:
-
Map: 一对一转换,将输入元素转换为新的元素
-
FlatMap: 一对多转换,将输入元素展平为零个、一个或多个元素
-
Filter: 过滤元素,只保留满足条件的元素
-
KeyBy: 按指定键对数据分组,返回 KeyedStream
-
Reduce: 对分组后的数据进行聚合
-
Fold:具有初始值的被 Keys 化数据流上的“滚动”折叠。将当前数据元与最后折叠的值组合并发出新值
val result: DataStream[String] = keyedStream.fold("start")((str, i) => { str + "-" + i })
// 解释:当上述代码应用于序列(1,2,3,4,5)时,输出结果“start-1”,“start-1-2”,“start-1-2-3”,...
-
Aggregations: :内置聚合函数如 sum, min, max 等
-
Window:将流数据按时间或数量分组到窗口(如滚动 / 滑动窗口),触发批量计算。
-
WindowAll:不分组,将所有数据放入同一个窗口(慎用,易导致单点瓶颈)
-
Window Apply:自定义窗口函数,对窗口内的全量数据进行处理(灵活性高但资源消耗大)
-
Window Reduce:增量聚合窗口内数据,仅保留中间结果(内存效率更高)
-
Window Fold:已弃用,类似 Reduce,但可自定义输出类型(现推荐用
AggregateFunction) -
Union:合并多个同类型流,保留所有元素(不保证顺序,支持无限流)
-
Window Join:基于相同 Key 和时间窗口对两个流进行内连接(如
TumblingEventTimeWindows -
Interval Join:基于时间间隔(如
eventTime ± 5秒)对两个 KeyedStream 进行关联 -
Window CoGroup:类似 Join,但允许更灵活的分组逻辑(如左外连接、右外连接)。
-
Connect:连接两个不同类型的流,共享状态但保留各自类型(如实时维表关联)
-
CoMap,CoFlatMap:对 Connect 后的流分别应用 Map/FlatMap 函数(如对主数据流和控制流分别处理)
-
Split:已弃用,将流按条件拆分为多个逻辑流(现推荐用
SideOutput) -
Select:已弃用,与 Split 配合,选择特定标签的数据流(现推荐用
getSideOutput)