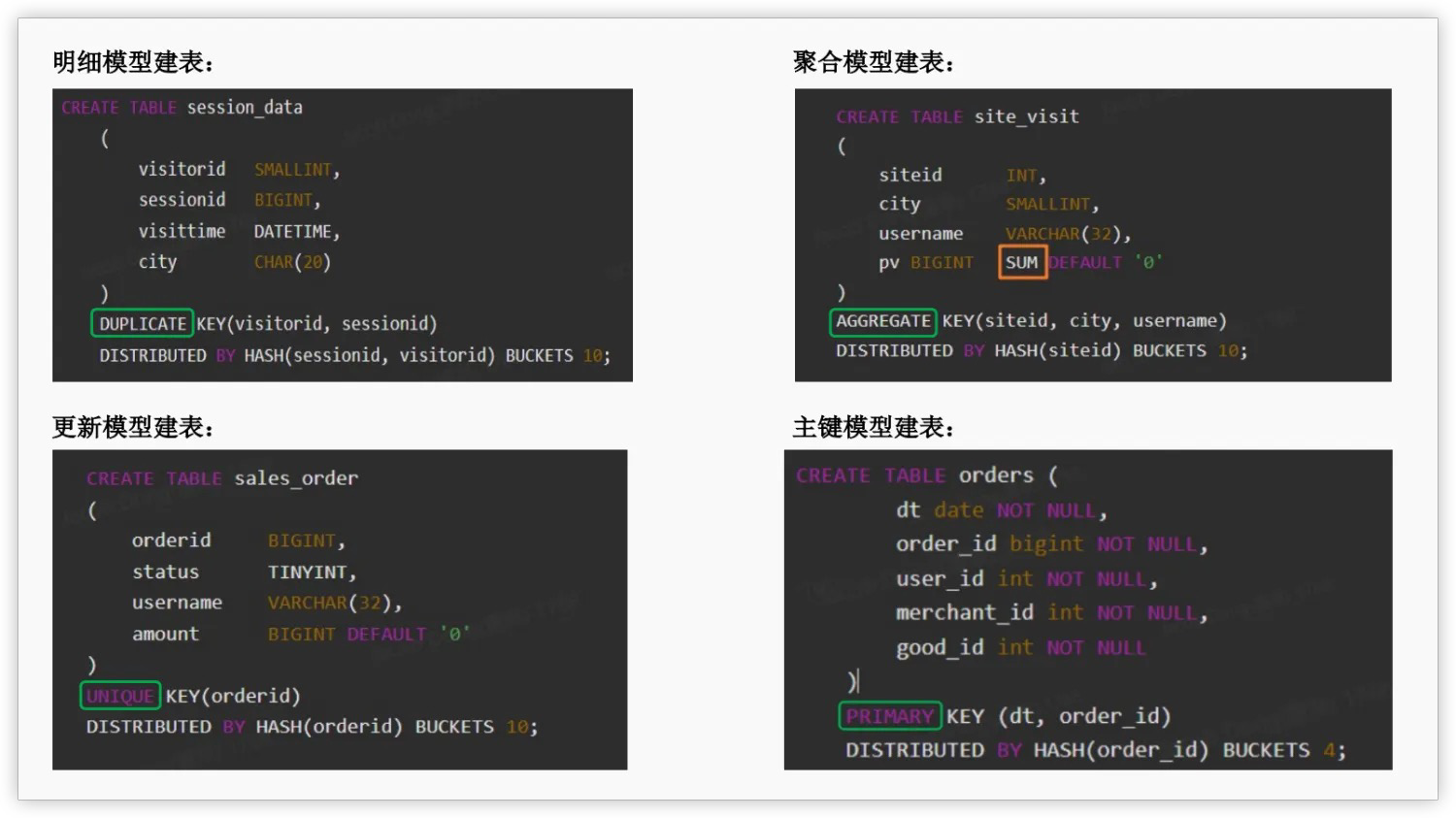
表创建
数据模型
| 数据模型 | 特点 | 适用场景 |
|---|---|---|
| 明细模型 | 用于保存和分析原始明细数据,以追加写为主要写入方式,数据写入后几乎无更新 | 日志,操作记录,设备状态采样,时序类数据等 |
| 聚合模型 | 用于保�存和分析汇总类(如:Max、Min、Sum、以及 Replace)数据,不需要查询明细数据。数据导入后实时完成聚合,数据写入后几乎无更新 | 按时间、地域、机构汇总数据等 |
| 更新模型 | 支持基于主键的更新,Merge-On-Read,用于保存和分析需要更新的数据 | 状态会发生变动的订单,设备状态等 |
| 主键模型 | 支持基于主键的更新,Delete-And-Insert,大批量导入时保证高性能查询。用于保存和分析需要更新的数据 | 状态会发生变动的订单,设备状态等 |
数据模型建表
排序键
在 StarRocks 中数据导入至数据模型,按照建表时指定的一列或多列排序和存储,这部分用于排序的列就称为排序键
最佳实践
- 将经常过滤的列作为 Sort Key
- 将经常 Group By 的列作为 Sort Key
- 数字列尽量放到 String 列之前
- 在建表语句中,排序键必须定义在其他列之前
- 排序列的顺序必须与表定义的列顺序一致
- 优先选择整型作为排序键
- 数据类型为 BITMAP、HLL 的列不支持作为排序键

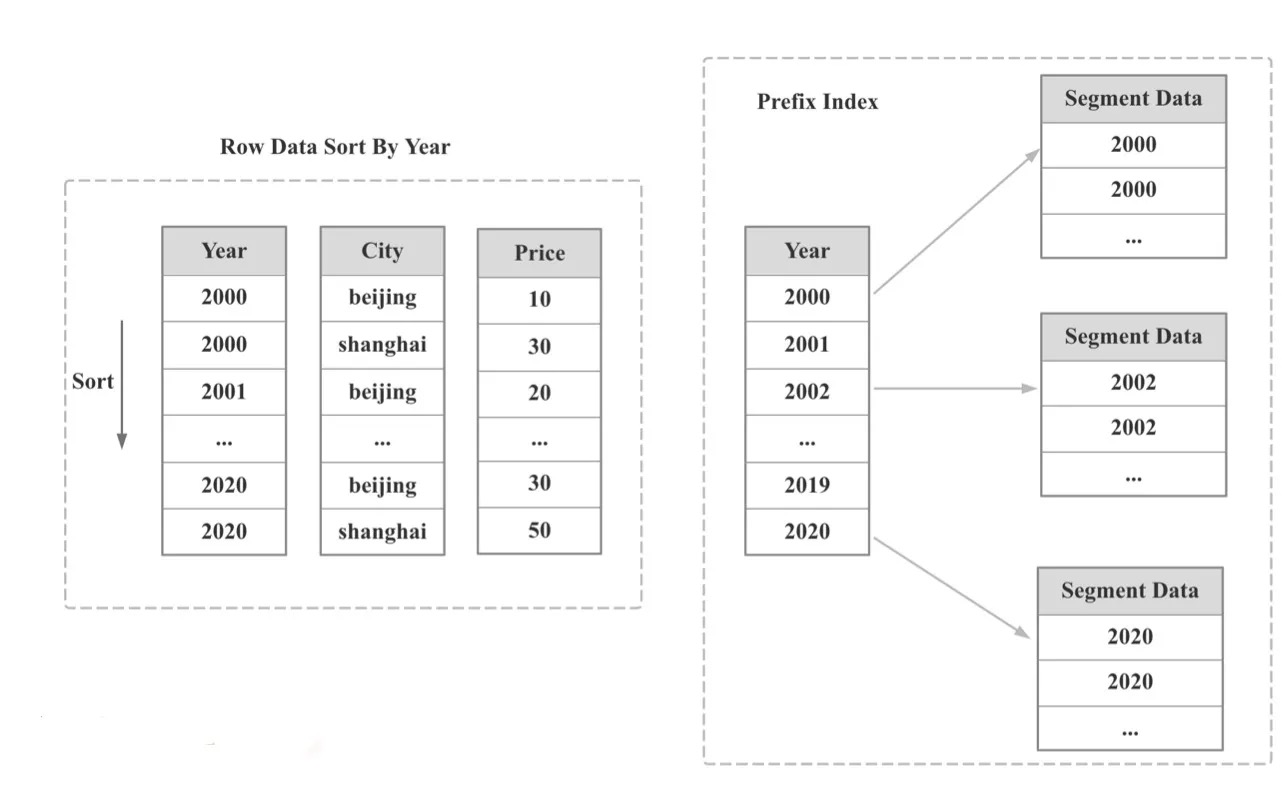
排序键(Sort key)与 前缀索引(Prefix key)
Prefix key 索引粒度1024行
Prefix key 索引Key:36字节
使用说明:
• 前缀索引列的数量不能超过3个。
• 前缀索引项的长度不能超过36 字节。
• 前缀索引中不能包含float 或double 类型的列。
• 前缀索引遇到varchar 类型的列会被截断,建议将varchar 列放在key 列中的在末尾位置。
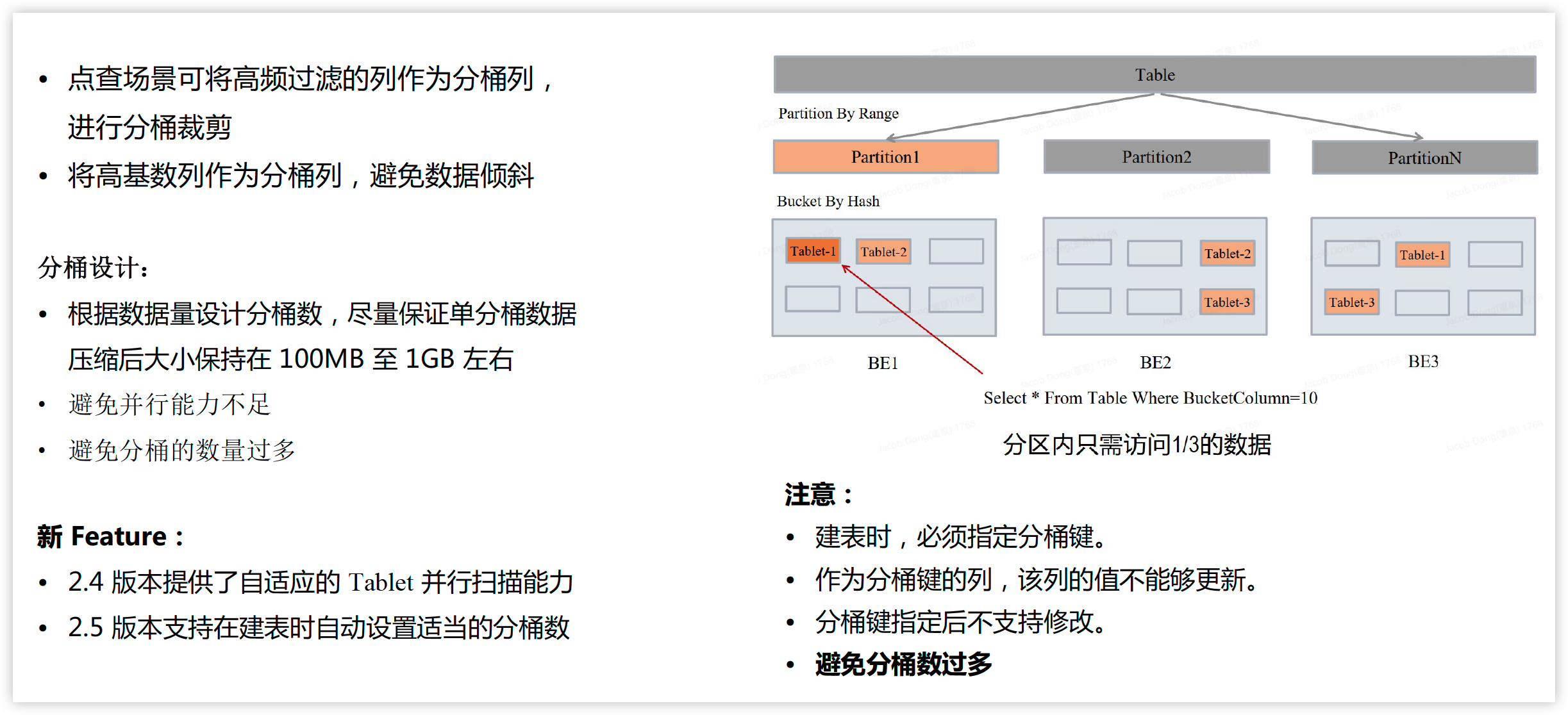
分区&分桶
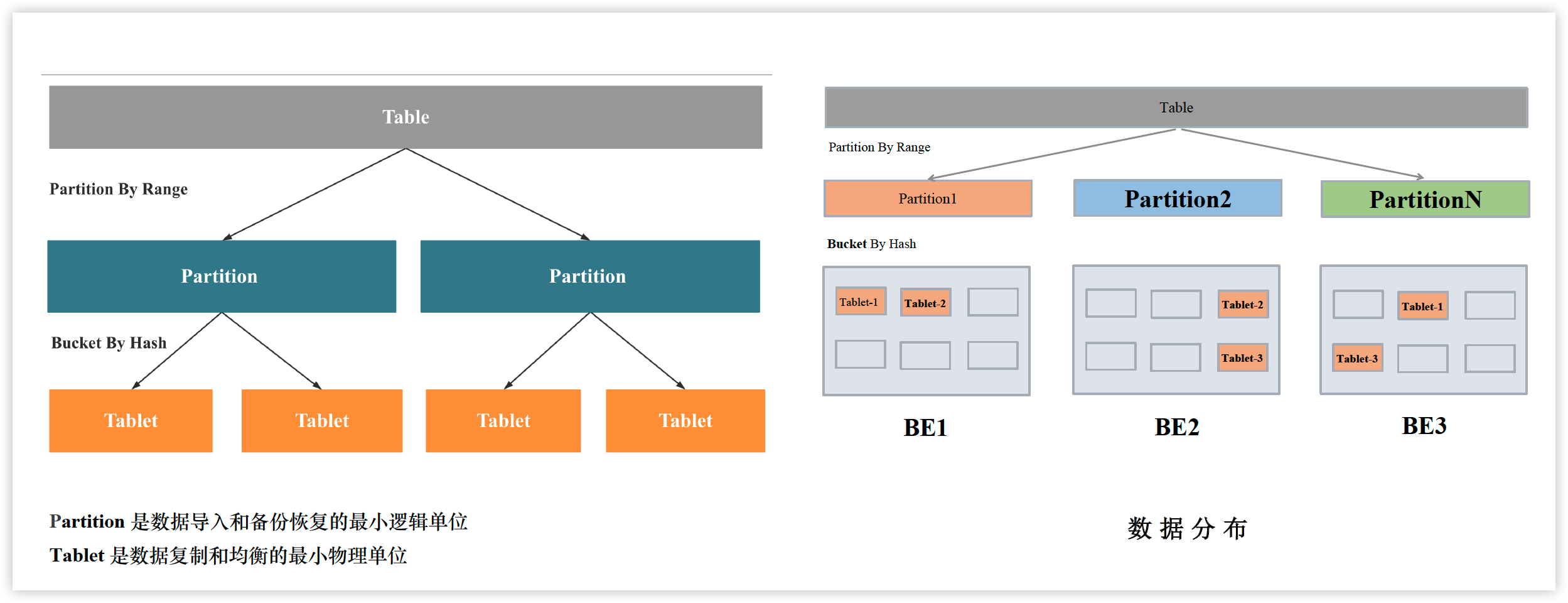
分区
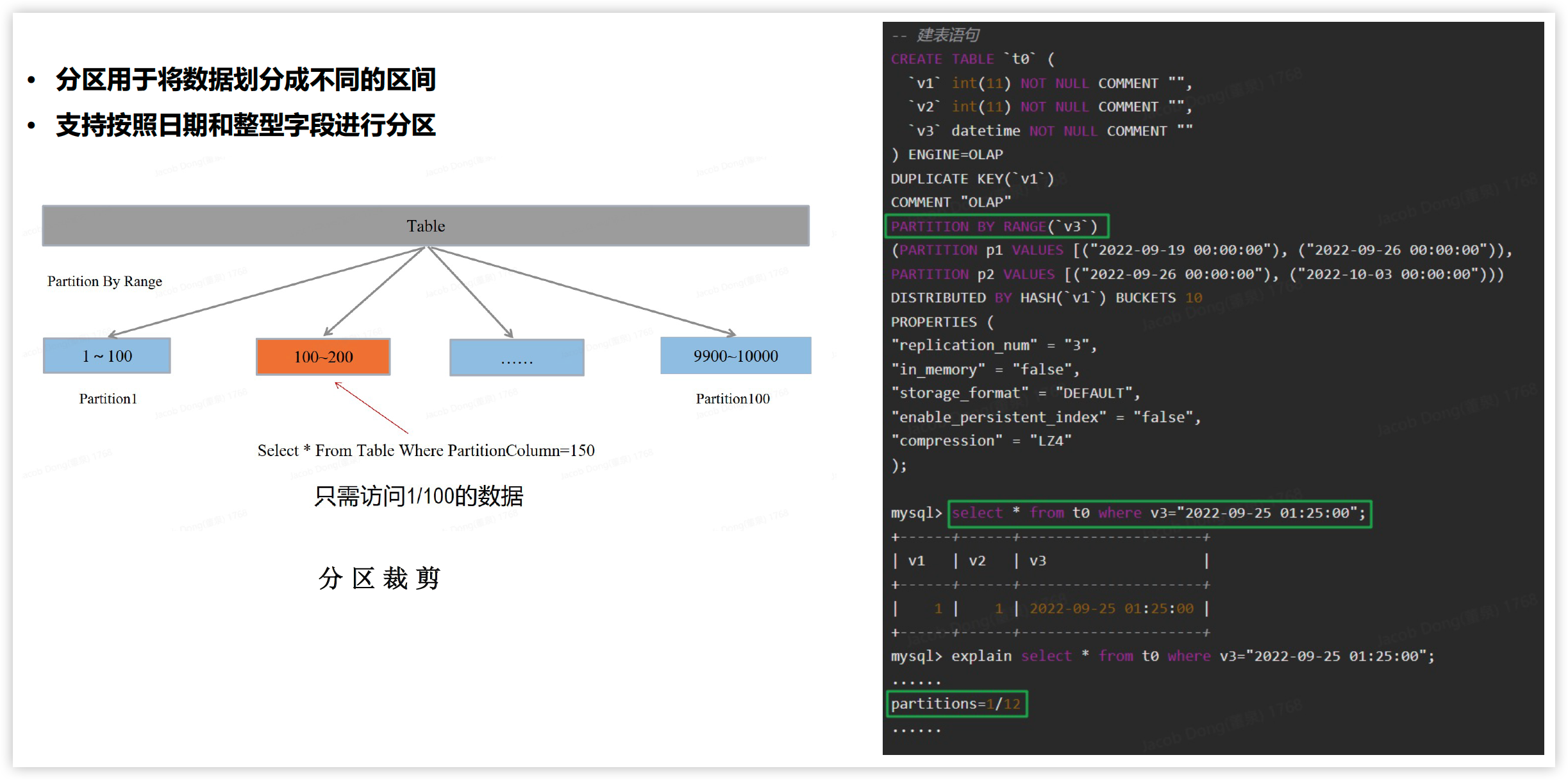
分桶
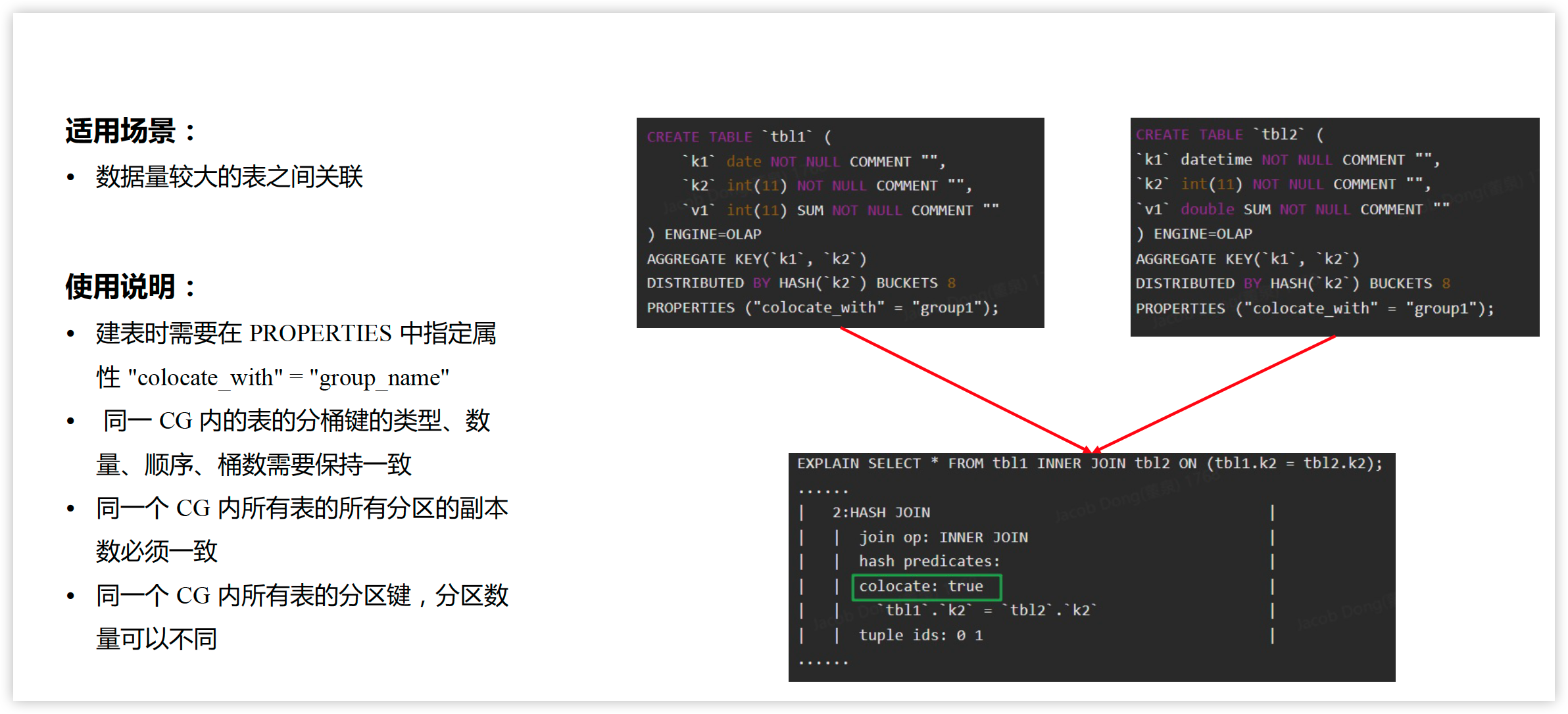
Colocate join
索引
Bitmap Index

Bloom Filter Index

物化视图
物化视图:提取某些维度、指标建立对用户透明的预聚合表
单表同步物化视图
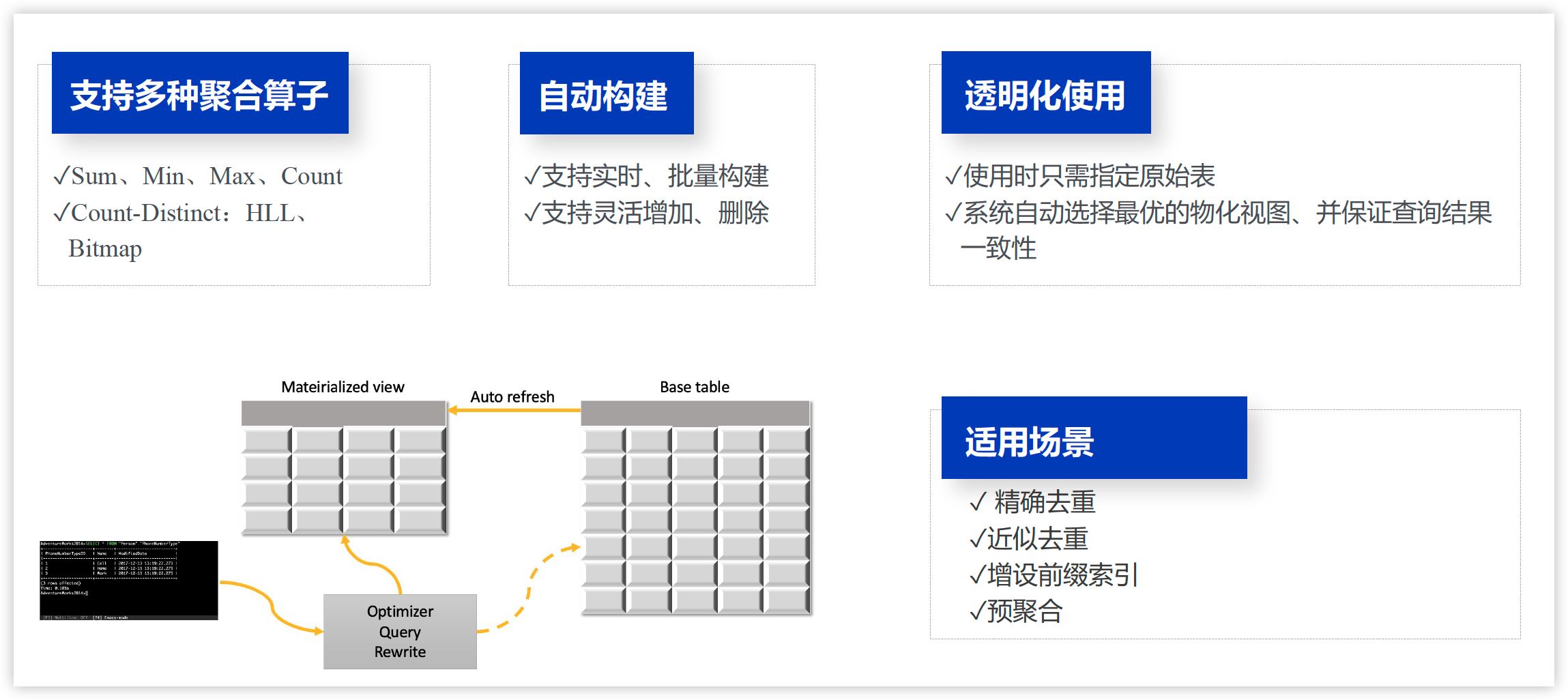
使用

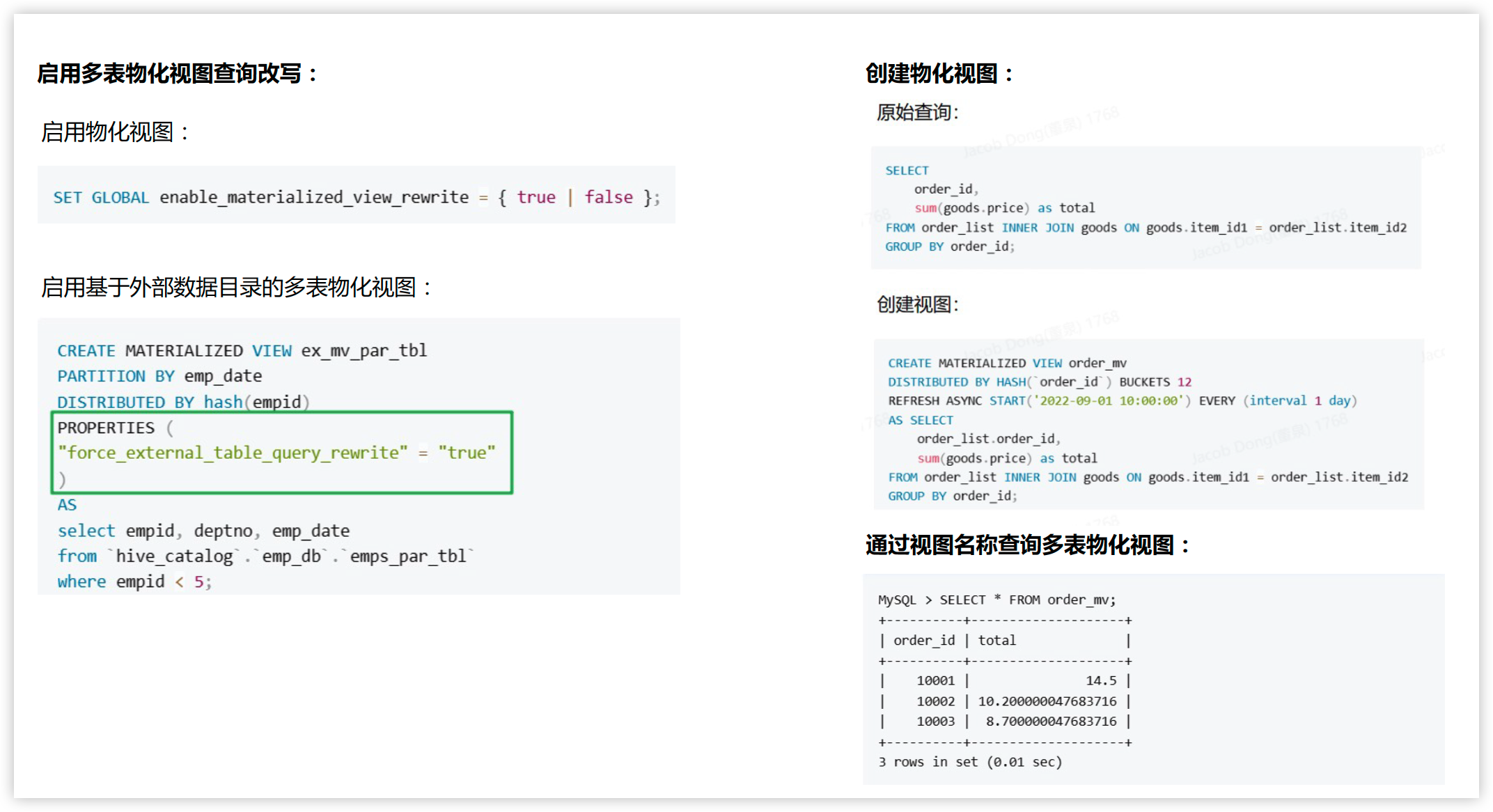
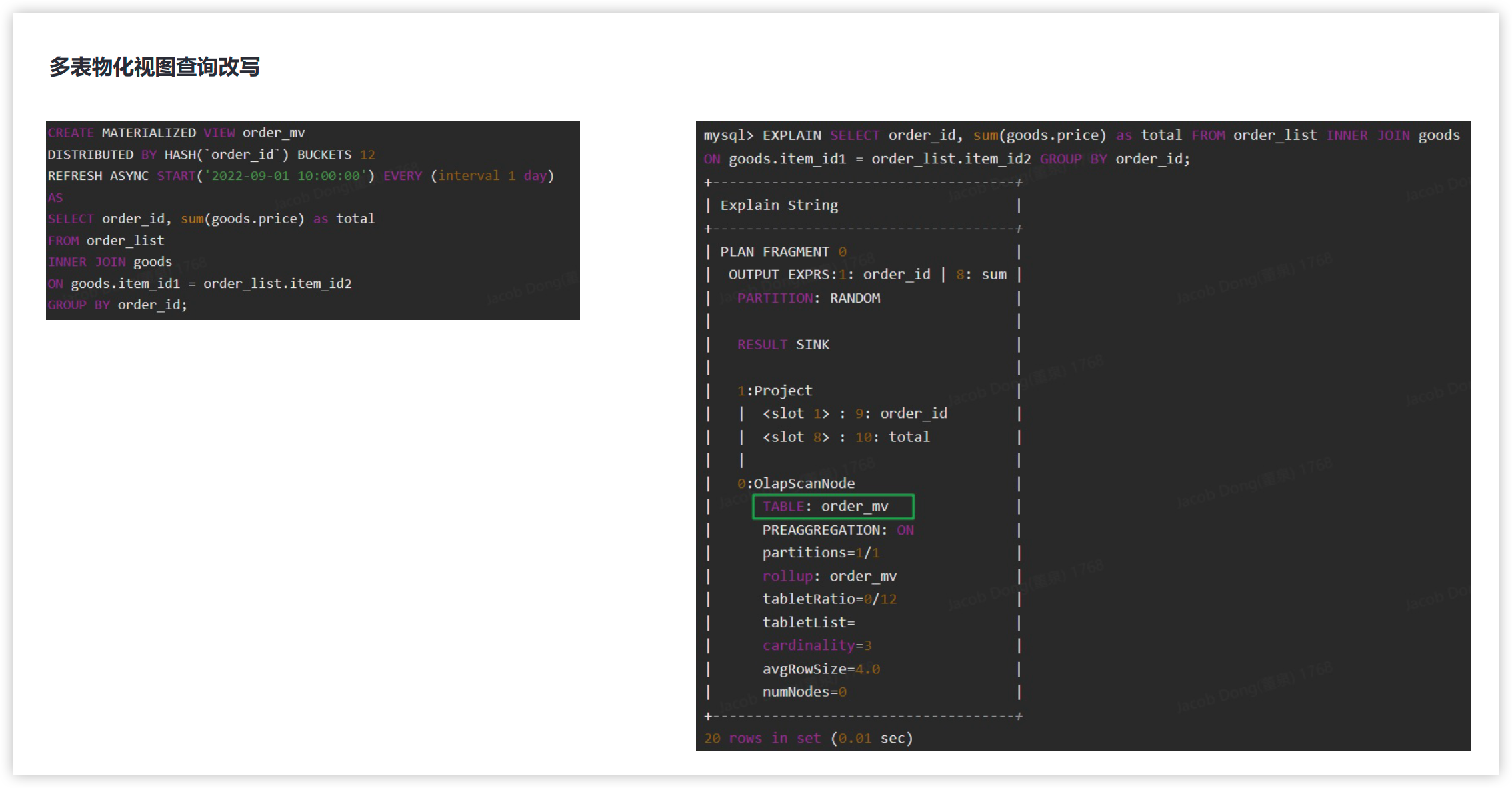
多表异步物化视图
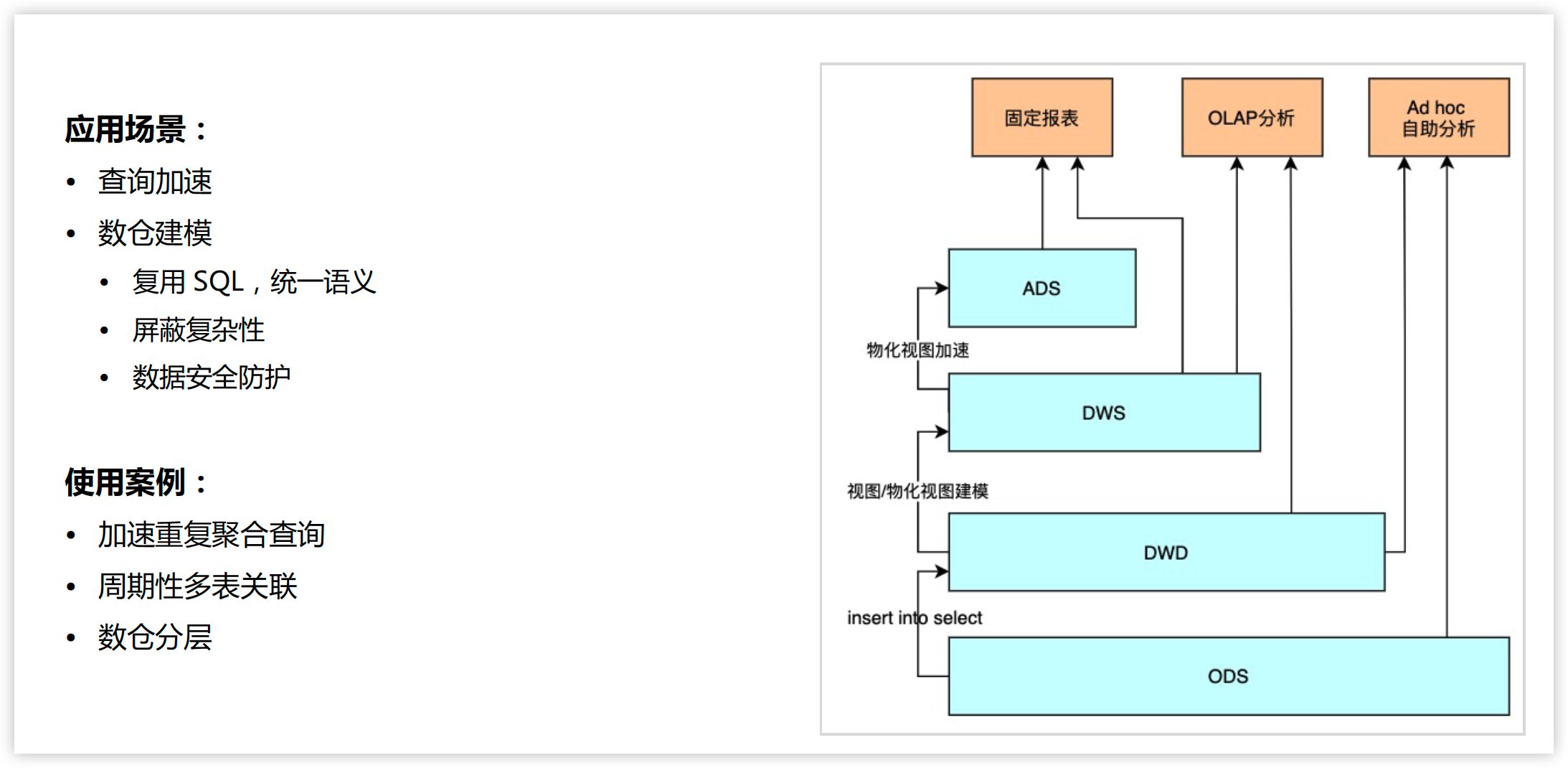
使用
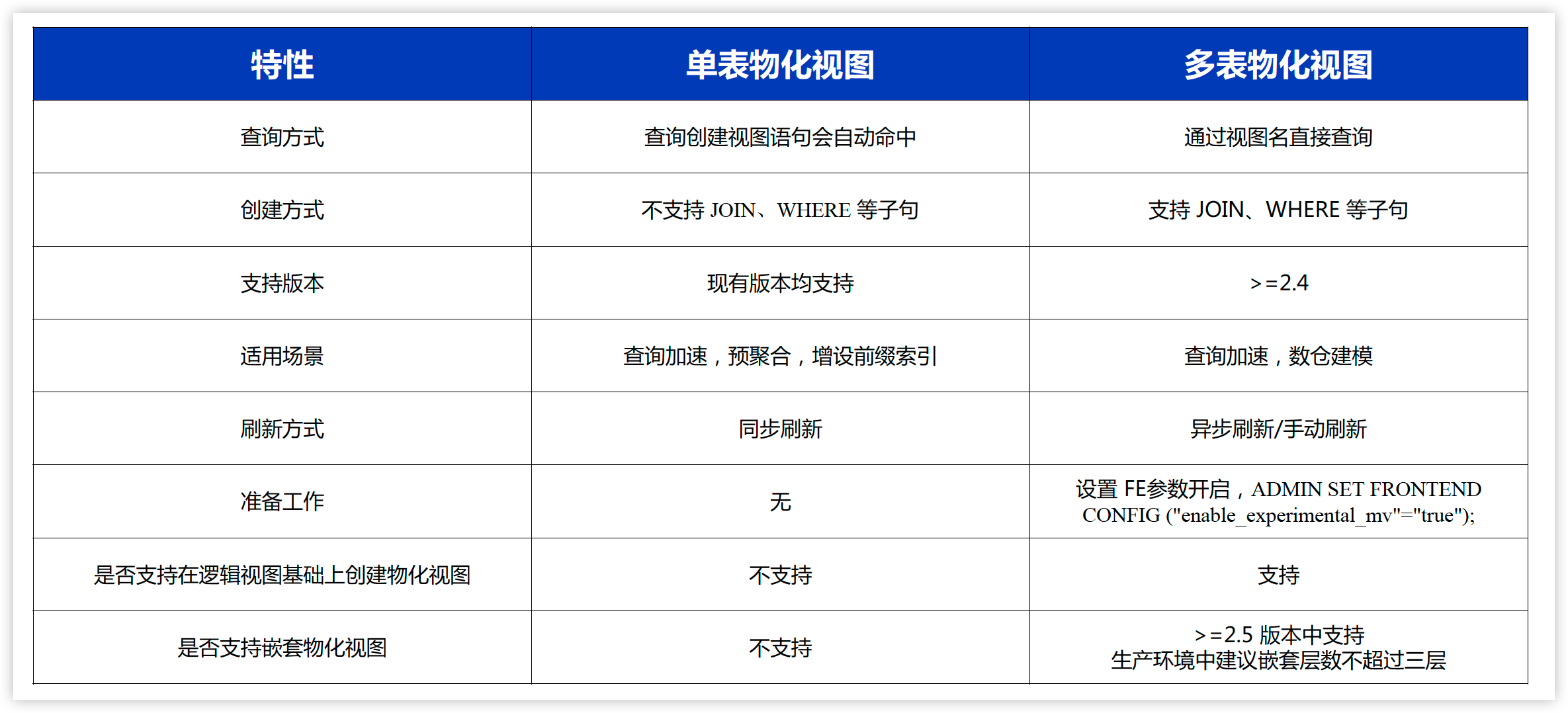
对比
多表关联
• Join Condition 的列,使用整型、DATE 类型,关联字段类型保持一致
• 在Join 之前,对表添加where 条件,充分发挥谓词下推
• 大表Join 使用Colocate join
• 通过Hint 方式调整表关联方式
• 多表物化视图
• 避免数据倾斜

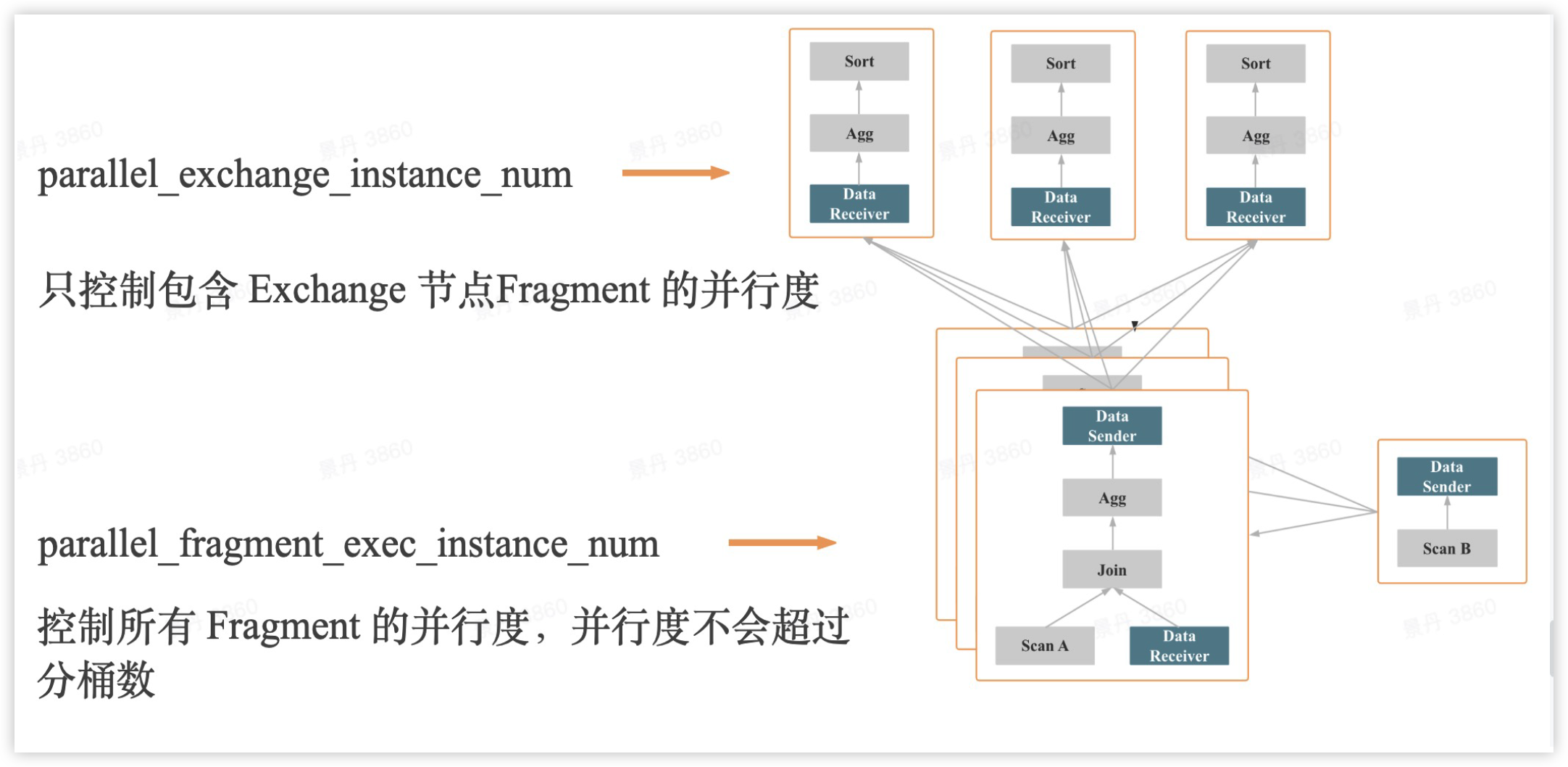
并行度设置

高并发优化

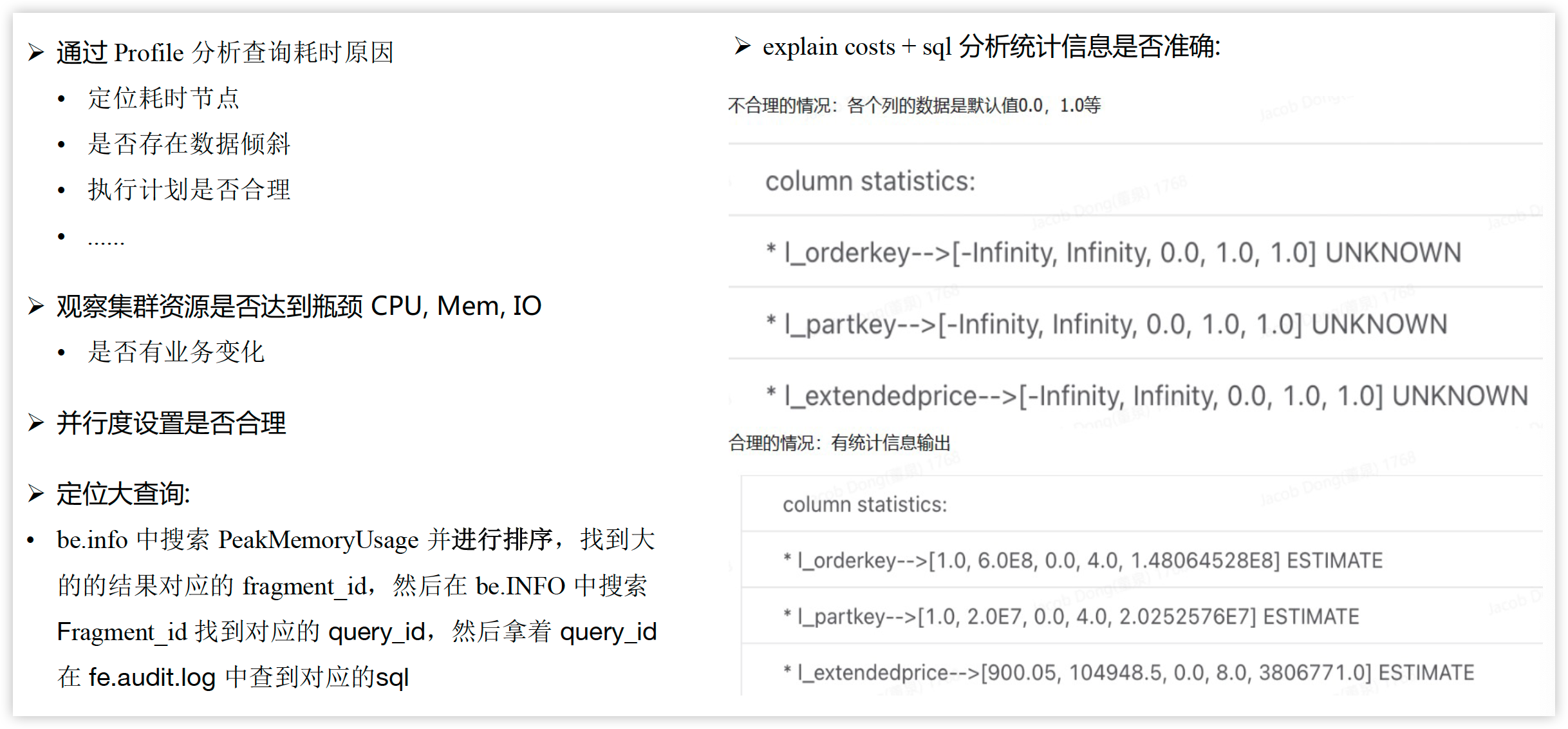
慢查询分析
Group By 优化

常见问题
单个查询的内存超限
报错信息:"Mem usage has exceed the limit of single query, You can change the limit by set session variable exec_mem_limit."
解决方案:需要修改session 变量: exec_mem_limit
查询总内存超限
报错信息:"Mem usage has exceed the limit of query pool"
解决方案:需�要优化SQL
BE 总内存超限
报错信息:"Mem usage has exceed the limit of BE"
解决方案
需要分析下具体哪些进程内存占用比较多,
通过以下命令查看内存占用明细:
curl -XGET -s http://BE_IP:BE_HTTP_PORT/metrics | grep
"^starrocks_be_.*_mem_bytes|^starrocks_be_tcmalloc_bytes_in_use"