Hdfs
Hadoop Distributed File System(HDFS)是Hadoop的核心组件之一,它是一个高度容错的分布式文件系统,设计用于在商用硬件上存储大量数据。
HDFS 有哪些组件
1. NameNode
NameNode是HDFS的主节点(Master Node),负责管理文件系统的元数据和文件的目录结构。它维护着文件系统树及所有文件和文件夹的元数据,并且管理客户端对文件的访问。具体功能包括:
- 元数据管理:NameNode存储文件系统树及所有文件和文件夹的元数据。这些元数据包括文件的目录结构、文件块的位置信息等。
- 文件操作:NameNode处理所有针对文件的创建、删除、重命名等操作请求。
- 数据块映射:NameNode维护着文件和数据块之间的映射关系,以及数据块在DataNode上的位置信息。
- 客户端请求处理:NameNode响应客户端的请求,提供文件的元数据,包括文件块的位置信息,以便客户端可以直接从DataNode读取数据。
2. DataNode
DataNode是HDFS的工作节点(Worker Node),负责实际存储文件系统中的数据。每个DataNode都存储着文件系统树的一部分数据块。具体功能包括:
- 数据存储:DataNode存储文件的数据块,并且每个数据块都有多个副本,以提高数据的可靠性和容错性。
- 数据块报告:DataNode定期向NameNode发送心跳信号和数据块报告,报告其存储的数据块信息。
- 数据块复制:当NameNode检测到某个数据块的副本数量不足时,DataNode会根据NameNode的指示复制数据块。
- 数据块自我修复:DataNode会定期检查存储的数据块的完整性,并自动复制丢失或损坏的数据块。
3. Secondary NameNode
Secondary NameNode是NameNode的辅助节点,它的主要作用是帮助NameNode合并编辑日志(Edit Logs)和文件系统映像(FsImage),以减少NameNode的负担并提高系统的稳定性。具体功能包括:
- 合并FsImage和Edit Logs:Secondary NameNode定期从NameNode获取FsImage和Edit Logs,然后合并它们,生成新的FsImage文件。
- 减少NameNode的负担:通过合并FsImage和Edit Logs,Secondary NameNode减轻了NameNode的负担,因为NameNode不需要在内存中维护所有的编辑日志。
- 辅助NameNode恢复:在NameNode失败的情况下,Secondary NameNode可以提供最新的FsImage和Edit Logs,帮助NameNode快速恢复。
HDFS Block的定义和作用
- 定义:HDFS将文件分割成多个数据块,默认大小为128MB或256MB。
- 作用:数据块是HDFS存储和处理的基础单位,它们允许Hadoop分布式处理大型文件
HDFS Block的特点
- 固定大小:HDFS中的块具有固定的大小,这种固定大小的设计有助于提高系统的性能和吞吐量。
- 分布式存储:HDFS的块是分布式存储在集群中的不同节点上的。
- 副本机制:为了确保数据的可靠性和容错能力,HDFS采用了副本机制。每个块通常会有多个副本分布在不同的数据节点上。
- 数据局部性:HDFS块的存储和处理都遵循数据局部性原则
提示
为什么从128M到256M?
- 传输速率:实际在工业生产中,磁盘传输速率为200MB/s时,一般设定block大小为256MB。
- 寻址时间:最佳传输损耗理论指出,在一次传输中,寻址时间占用总传输时间的1%时,本次传输的损耗最小,为最佳性价比传输。
- 硬件发展:随着硬件的发展,磁盘的读写速率提高,因此可以将block大小调整到256MB��或更大
HDFS 副本机制
HDFS将文件分割成多个数据块(默认大小为128MB或256MB),并将这些数据块存储在集群中的不同DataNode上。为了提供容错性,HDFS会自动将每个数据块的副本存储在不同的DataNode上,默认是3个副本
副本放置策略
HDFS的副本放置策略旨在优化数据的可靠性和访问性能:
- 第一个副本:通常存储在客户端所在的DataNode上,如果客户端不在集群内,则随机选择一个DataNode。
- 第二个副本:存储在不同的机架上的DataNode,以提高跨机架故障的容错能力。
- 第三个副本:存储在与第二个副本相同机架的其他DataNode上。
- 额外副本:如果有更多副本,它们将随机分布在不同的DataNode上。
副本的管理和维护
- 数据块报告:DataNode定期向NameNode发送心跳信号和数据块报告,报告其存储的数据块信息。
- 副本复制:当NameNode检测到某个数据块的副本数量不足时,NameNode会指示DataNode复制数据块。
- 数据块自我修复:DataNode会定期检查存储的数据块的完整性,并自动复制丢�失或损坏的数据块。
容错和数据恢复
- 数据损坏处理:客户端读取完DataNode上的块之后会进行checksum验证,如果读取DataNode时出现错误,客户端会通知NameNode,然后再从下一个拥有该block副本的DataNode继续读。
- DataNode故障处理:当DataNode突然挂掉了,客户端接收不到这个DataNode发送的ack确认,客户端会通知NameNode,NameNode检查该块的副本与规定的不符,NameNode会通知DataNode去复制副本,并将挂掉的DataNode作下线处理。
高可用性和性能优化
- NameNode的高可用性:在Hadoop 2.x及以后的版本中,可以通过配置多个NameNode来实现高可用性,确保在主NameNode失败时,备用NameNode可以接管工作。
- 数据本地性:HDFS会尽量将数据块存储在离计算任务最近的DataNode上,以减少网络传输的开销,提高数据处理的效率。
HDFS的副本机制通过在多个节点上存储数据块的多个副本,确保了数据的高可靠性和高可用性。同时,通过优化副本的放置策略和数据块的管理,HDFS能够有效地利用集群资源,提高数据的访问速度和处理效率。
HDFS 读数据流程
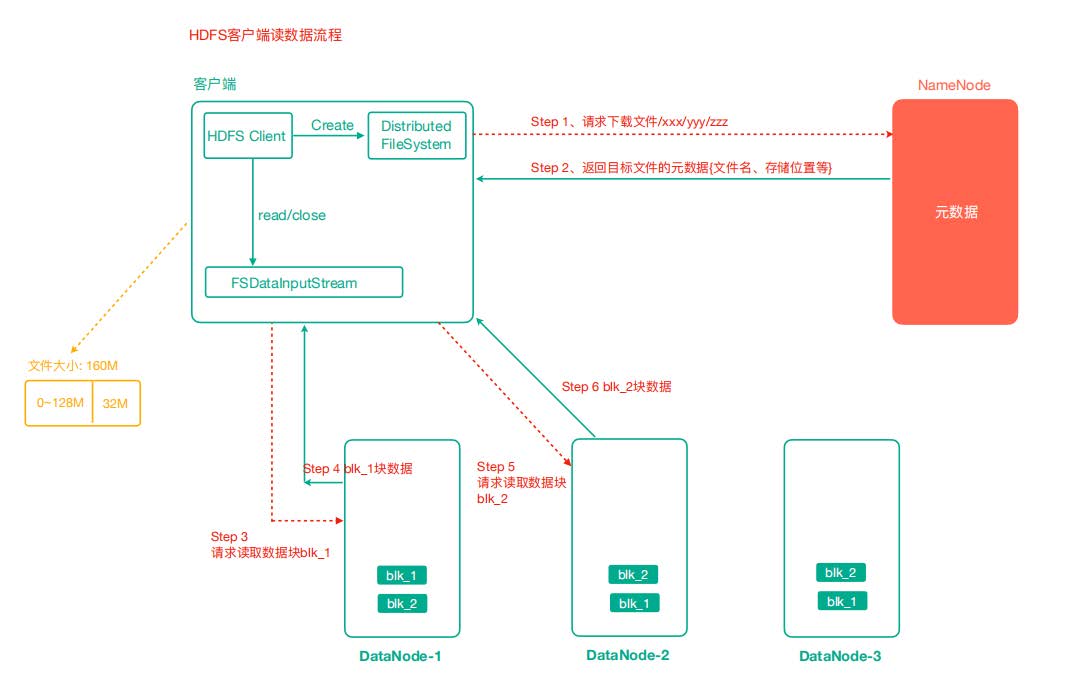
- 客户端通过Distributed FileSystem向NameNode请求下载文件,NameNode通过查询元数据, 找到文件块所在的DataNode地址。
- 挑选一台DataNode(就近原则,然后随机)服务器,请求读取数据。
- DataNode开始传输数据给客户端(从磁盘里面读取数据输入流,以Packet为单位来做校验)。
- 客户端以Packet为单位接收,先在本地缓存,然后写入目标文件。
HDFS 写数据流程
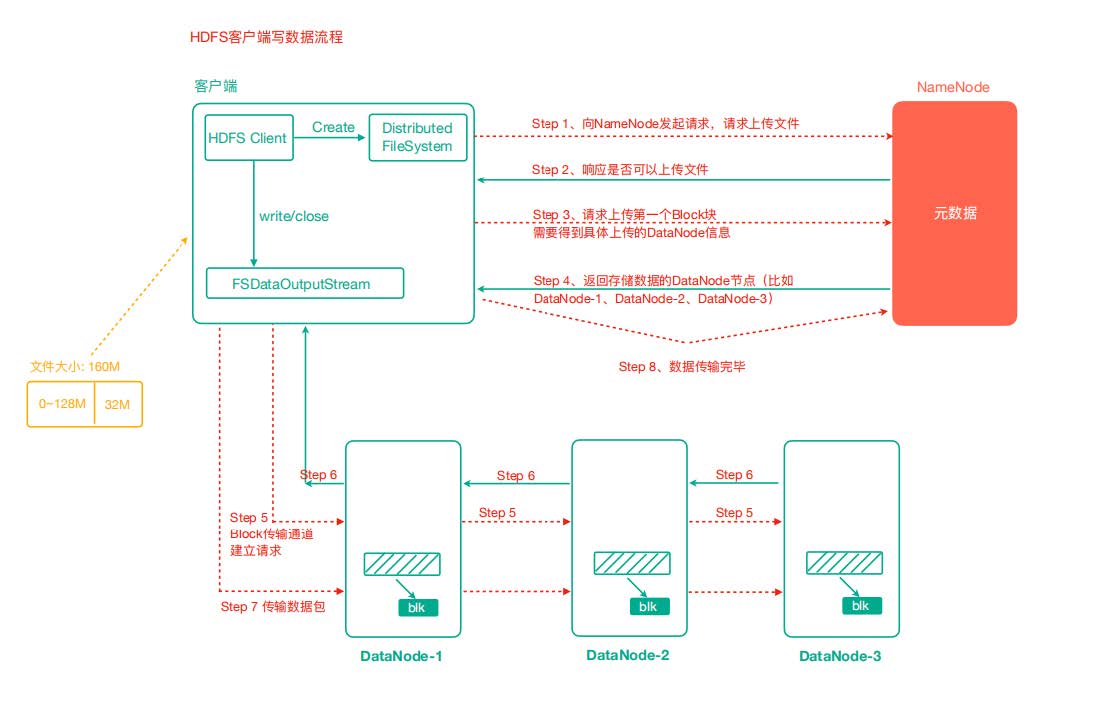
- 客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件 是否已存在,父目录是否存在。
- NameNode返回是否可以上传。
- 客户端请求第一个 Block上传到哪几个 DataNode 服务器上。
- NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
- 客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后 dn2调用dn3,将这个通信管道建立完成。
- dn1、dn2、dn3逐级应答客户端。
- 客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单 位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个确认队列 等待确认。
- 当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行 3-7步)