Yarn
YARN(Yet Another Resource Negotiator)是Hadoop的资源管理器,它负责集群资源的管理和调度,使得Hadoop能够更有效地处理各种数据密集型应用。
YARN的主要组件有哪些
1. ResourceManager (RM)
ResourceManager是YARN的全局资源管理器,负责整个系统的资源分配和任务调度。它的主要职责包括:
- 资源管理:监控集群资源(如内存、CPU等)的使用情况,并将资源分配给各个应用程序。
- 调度管理:根据调度策略(如Fair Scheduler、Capacity Scheduler等)决定资源分配给哪个应用程序。
- 应用程序管理:管理所有提交到YARN的应用程序,包括应用程序的生命周期管理。
- 集群管理:提供集群资源的全局视图,监控集群健康状态,处理节点故障等。
2. NodeManager (NM)
NodeManager是YARN在每个节点上的代理,负责管理单个节点的资源和任务执行。它的主要职责包括:
- 资源管理:监控和报告节点的资源使用情况(如内存、CPU等),并根据ResourceManager的指令使用这些资源。
- 任务管理:启动、监控和管理运行在节点上的容器(Container),包括应用程序的各个任务。
- 日志管理:收集和管理应用程序任务的日志信息。
- 心跳机制:定期向ResourceManager发送心跳信号,报告节点状态和资源使用情况。
3. ApplicationMaster (AM)
ApplicationMaster是YARN中代表单个应用程序的进程,负责应用程序的资源请求和任务调度。它的主要职责包括:
- 资源请求:根据应用程序的需求向ResourceManager请求资源。
- 任务调度:根据应用程序的逻辑,将任务分配给NodeManager上的容器执行。
- 任务监控:监控应用程序中各个任务的执行状态,处理任务失败和重试。
- 进度报告:向ResourceManager报告应用程序的进度和状态。
4. Container
Container是YARN中资源分配的基本单位,封装了一定量的内存、CPU等资源。每个Container运行一个应用程序的任务,包括Map任务、Reduce任务等。Container的主要职责包括:
- 资源封装:封装了一定量的内存、CPU等资源,为应用程序任务提供运行环境。
- 任务执行:运行应用程序的任务,包括Map任务、Reduce任务等。
- 资源隔离:通过Linux容器技术(如cgroups)实现资源隔离,确保不同任务之间的资源互不影响。
5. Scheduler(�调度器)
YARN的调度器负责根据ResourceManager的调度策略,决定资源分配给哪个应用程序。常见的调度器包括:
- Capacity Scheduler:基于容量的调度策略,允许多个组织共享集群资源。
- Fair Scheduler:基于公平性的调度策略,确保所有应用程序都能获得公平的资源分配。
Yarn 架构
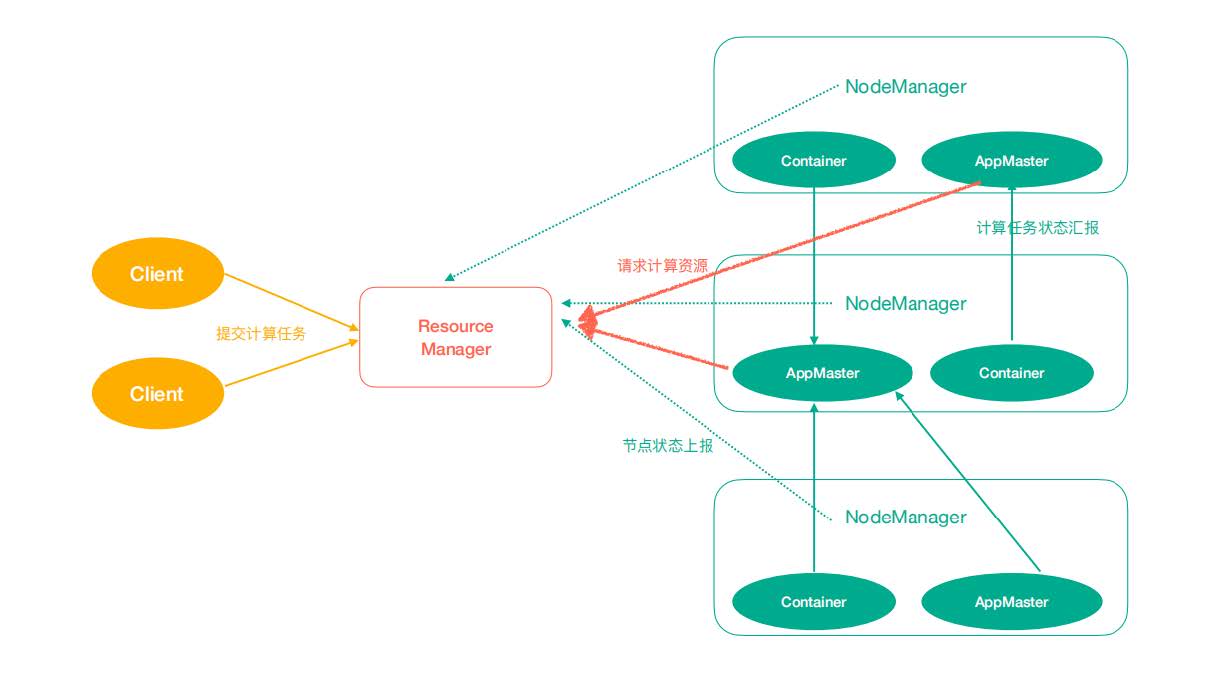
ResourceManager(rm):处理客户端请求、启动/监控ApplicationMaster、监控NodeManager、资源分配与调度;
NodeManager(nm):单个节点上的资源管理、处理来自ResourceManager的命令、处理来自ApplicationMaster的命令;
ApplicationMaster(am):数据切分、为应用程序申请资源,并分配给内部任务、任务监控与容错。
Container:对任务运行环境的抽象,封装了CPU、内存等多维资源以及环境变量、启动命令等任务运行相关的信息。
Yarn 任务提交流程
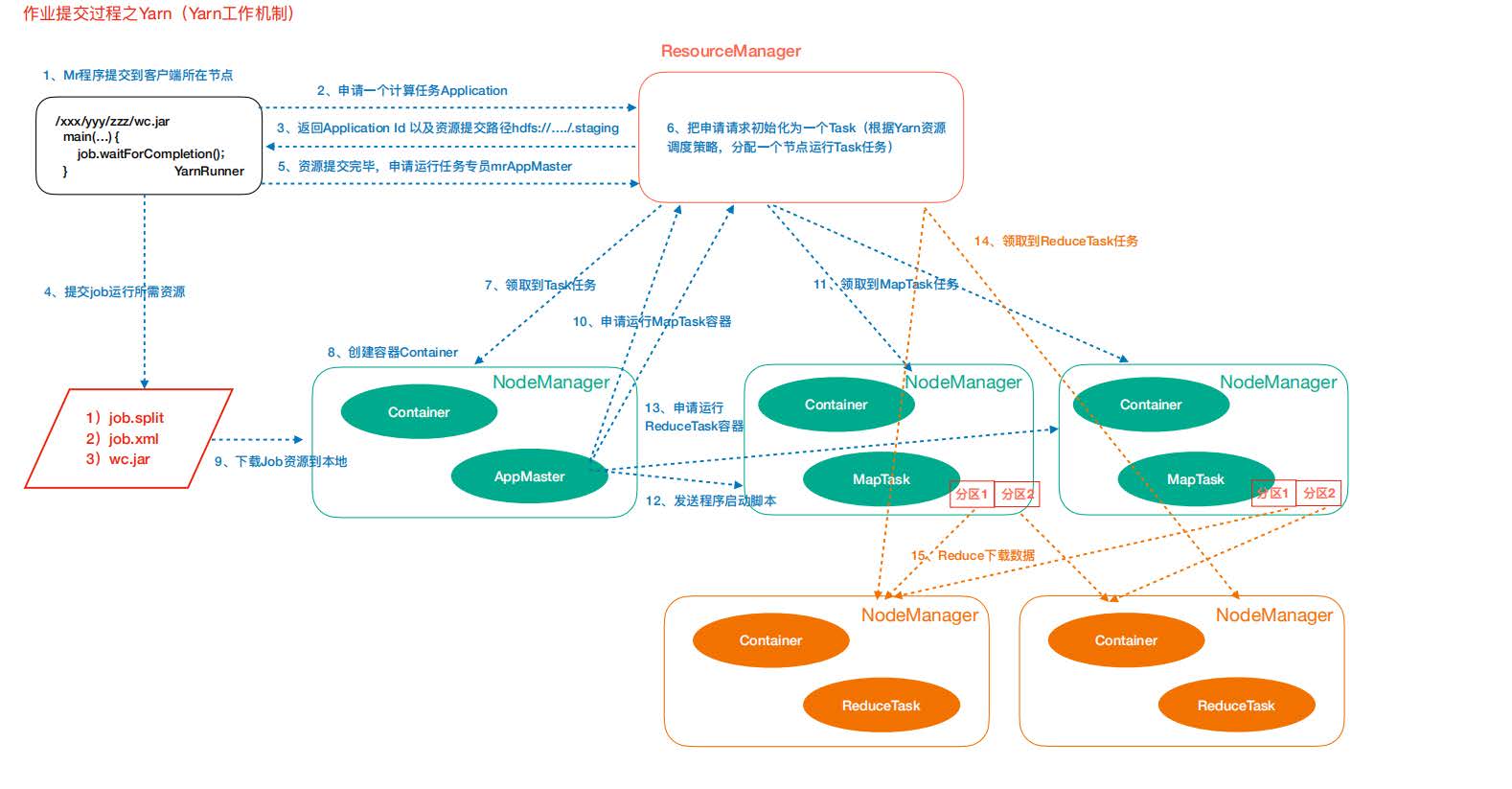 作业提交过程之YARN
作业提交过程之YARN
作业提交
- 第1步:Client调用job.waitForCompletion方法,向整个集群提交MapReduce作业。
- 第2步:Client向RM申请一个作业id。
- 第3步:RM给Client返回该job资源的提交路径和作业id。
- 第4步:Client提交jar包、切片信息和配置文件到指定的资源提交路径。
- 第5步:Client提交完资源后,向RM申请运行MrAppMaster。
作业初始化
- 第6步:当RM收到Client的请求后,将该job添加到容量调度器中。
- 第7步:某一个空闲的NM领取到该Job。
- 第8步:该NM创建Container,并产生MRAppmaster。
- 第9步:下载Client提交的资源到本地。
任务分配
- 第10步:MrAppMaster向RM申请运行多个MapTask任务资源。
- 第11步:RM将运行MapTask任务分配给另外两个NodeManager,另两个NodeManager分 别领取任务并创建容器。
任务运行
- 第12步:MR向两个接收到任务的NodeManager发送程序启动脚本,这两个NodeManager 分别启动MapTask,MapTask对数据分区排序。
- 第13步:MrAppMaster等待所有MapTask运行完毕后,向RM申请容器,运行ReduceTask。
- 第14步:ReduceTask向MapTask获取相应分区的数据。
- 第15步:程序运行完毕后,MR会向RM申请注销自己。
进度和状态更新
YARN中的任务将其进度和状态返回给应用管理器, 客户端每秒(通过
mapreduce.client.progressmonitor.pollinterval设置)向应用管理器请求进度更新, 展示给用
户。
作业完成
除了向应用管理器请求作业进度外, 客户端每5秒都会通过调用waitForCompletion()来检查作
业是否完成。时间间隔可以通过mapreduce.client.completion.pollinterval来设置。作业完
成之后, 应用管理器和Container会清理工作状态。作业的信息会被作业历史服务器存储以备
之后用户核查。
Yarn 调度策略
1、FIFO : 整个集群提交的作业都是用一个队列来进行服务,根据提交作业的顺序来运行,先来先服务
2、容量调度器 : 将整个集群的资源分为队列,每个队列之间的资源互不干扰,可分为生产和开发环境,且可以在每一个对队列里面使用FIFO调度策略
3、Fair Scheduler(资源调度器): 支持多个队列,每个队列配置一定的资源,每个队列中的job任务公平共享所在队列的所有资源,队列中的job任务都是��按照优先级分配资源,优先级越高分配的资源越多,会公平保证每个job都会分配到资源
Yarn 容错机制
Apache YARN(Yet Another Resource Negotiator)作为 Hadoop 的资源管理层,提供了多种容错机制来确保集群的高可用性和任务的可靠执行。以下是 YARN 的主要容错机制:
1. ResourceManager 容错机制
ResourceManager 是 YARN 的核心组件之一,负责资源的分配和调度。为了提高其高可用性,YARN 提供了以下容错机制:
-
ResourceManager HA(高可用性):
- YARN 支持在集群中配置多个 ResourceManager 实例(通常为一个活跃状态,另一个为备用状态)。当活跃的 ResourceManager 发生故障时,备用的 ResourceManager 会接管,保证集群的正常运行。
- 为了实现高可用性,YARN 使用 Zookeeper 来协调活跃和备用 ResourceManager 之间的状态。
-
State Store:
- ResourceManager 使用持久化存储(如 HDFS)来保存集群的状态信息。这样即使 ResourceManager 崩溃,也可以从存储中恢复任务的状态。
2. NodeManager 容错机制
NodeManager 负责单个节点上的资源管理和任务监控。为了提高任务的可靠性,YARN 提供了以下容错机制:
- 节点监控与恢复:
- NodeManager 会定期向 ResourceManager 发送心跳信息。如果 ResourceManager 在一定时间内未收到心跳,认为节点失效,并将其上运行的任务重新分配到其他节点。
- 容器(Container)重启:
- 如果一个容器在运行时失败,NodeManager 可以重新启动该容器,以确保任务的继续执行。
3. ApplicationMaster 容错机制
ApplicationMaster 是每个 YARN 应用程序的主控程序,负责协调应用程序的执行。为了提高应用程序的容错性,YARN 提供了以下机制:
- ApplicationMaster 重启:
- 如果 ApplicationMaster 失败,YARN 可以重新启动 ApplicationMaster 并恢复应用程序的执行状态。
- ApplicationMaster 可以将应用程序的状态持久化(例如到 HDFS),以便在重启后恢复任务的进度。
4. 数据本地化与容错
YARN 在分配任务时,尽量将任务调度到数据所在的节点上执行(数据本地化)。如果某个节点不可用,YARN 可以将任务分配到其他具有数据副本的节点上,这种机制减少了任务失败的概率。
5. Speculative Execution(推测执行)
YARN 支持推测执行机制,如果某个任务执行速度较慢,系统会启动该任务的副本以加快进度。最终只保留完成最早的副本,这种机制可以减少长尾任务对整体执行时间的影响。
6. 容错的监控与告警
YARN 集成了多种监控工具,可以对集群的健康状况进行监控,并在发现问题时触发告警,以便及时处理故障。
总结
Apache YARN 通过多种容错机制,包括 ResourceManager 的高可用性、NodeManager 的任务恢复、ApplicationMaster 的重启、数据本地化、推测执行以及监控告警,来确保大规模数据处理任务的可靠性和高可用性。这些机制使得 YARN 能够在不稳定的硬件环境中继续可靠地运行。