概念原理
本文主要介绍Spark的基础概念和架构相关面试题
简述一下 Spark?
Spark是一种基于内存的开源分布式计算框架,用于快速处理大规模数据。它支持批处理、实时流处理、机器学习和SQL查询等多种场景,具有高扩展性和容错性。
核心组件包括Spark Core(基础引擎)、Spark SQL(结构化数据处理)、Spark Streaming(实时流处理)、MLlib(机器学习库)和GraphX(图数据处理)。
运行模式有本地模式(单机测试)和集群模式(Hadoop YARN、Mesos、Kubernetes)。
Spark 和 Hadoop 的区别
1.计算模式
- Hadoop:基于磁盘的批处理框架,依赖Hadoop MapReduce,适合离线数据分析,计算速度相对较慢。
- Spark:基于内存的计算框架,支持多种计算模式(批处理�、实时流处理、机器学习等),速度更快。
2.性能
- Hadoop:主要依赖磁盘存储和读取数据,I/O开销大,处理速度慢。
- Spark:大量依赖内存计算,减少了磁盘I/O操作,计算速度比Hadoop快10-100倍。
3.易用性
- Hadoop:MapReduce编程模型相对复杂,开发人员需要编写较多代码。
- Spark:提供Scala、Python、Java和R等多种语言的API,编程更简单,同时支持SQL和DAG执行计划优化。
4.实时性
- Hadoop:主要用于批处理,不适合实时数据处理。
- Spark:通过Spark Streaming模块,支持实时流处理,可快速处理实时数据。
5.容错机制
- Hadoop:通过数据冗余和任务重试来实现容错,依赖HDFS的三副本机制。
- Spark:通过RDD(弹性分布式数据集)的容错性,利用数据的“血统”(lineage)信息在节点故障时重新计算丢失的数据,减少了数据冗余存储。
6.应用场景
- Hadoop:适合大规模批量处理和存储海量数据,例如日志存储和简单统计分析。
- Spark:适合复杂的数据处理、机器学习、实时数据分析等场景,如金融风险评估和社交网络分析。
Spark 为什么快?
-
Spark之所以快,主要归功于以下几个关键因素:
- 内存计算:
- Spark支持将数据保留在内存中进行处理,这大大减少了与磁盘I/O操作相关的延迟。内存中的数据访问速度比磁盘快得多,从而加快了数据处理速度。
- 惰性计算和智能优化:
- Spark使用惰性计算(Lazy Evaluation),意味着它不会立即执行计算,而是等到需要结果时才进行。这种机制允许Spark优化整个计算图,合并多个操作以减少任务数量和数据传输。
- 高效的执行引擎:
- Spark的执行引擎能够智能地优化执行计划,包括预测任务的执行顺序和数据分区,以减少数据的移动和提高并行处理效率。
- 血统(Lineage)机制:
- 当数据因为节点故障而丢失时,Spark可以通过血统信息重新计算丢失的数据,而不是像Hadoop那样重新启动整个作业,这减少了容错所需的时间。
提示Spark比MapReduce快,主要是因为它以内存计算为核心,优化了数据处理流程,减少了对磁盘I/O的依赖,而MapReduce主要设计为磁盘计算,即使在有内存资源的情况下也倾向于将数据写入磁盘。
- 内存计算:
Spark 核心组件
Master(Cluster Manager):集群中的管理节点,管理集群资源,通知 Worker 启动 Executor 或 Driver。
Worker :集群中的工作节点,负责管理本节点的资源,定期向Master汇报心跳,接收Master的命令,启动Driver或 Executor。
Driver:执行 Spark 应用中的 main 方法,负责实际代码的执行工作。其主要任务:
-
负责向集群申请资源,向master注册信息
-
Executor启动后向 Driver 反向注册
-
负责作业的解析、生成Stage并调度Task到Executor上
-
监控Task的执行情况,执行完毕后释放资源
-
通知 Master 注销应用程序
Executor:是一个 JVM 进程,负责执行具体的Task。Spark 应用启动时, Executor节点被同时启动,并且始终伴随
着整个 Spark 应用的生命周期而存在。如果有 Executor 节点发生了故障或崩溃, 会将出错节点上的任务调度到其他
Executor 节点上继续运行。Executor 核心功能:
- 负责运行组成 Spark 应用的任务,并将结果返回给 Driver 进程
- 通过自身的 Block Manage 为应用程序缓存RDD
Spark 任务执行流程?
-
SparkContext 向资源管理器注册并向资源管理器申请运行 Executor。
-
资源管理器分配 Executor,然后资源管理器启动 Executor。
-
Executor 发送心跳至资源管理器。
-
SparkContext 构建 DAG 有向无环图。
-
将 DAG 分解成 Stage(TaskSet)。
-
把 Stage 发送给 TaskScheduler。
-
Executor 向 SparkContext 申请 Task。
-
TaskScheduler 将 Task 发送给 Executor 运行。 - 同时 SparkContext 将应用程序代码发放给 Executor。
-
Task 在 Executor 上运行,运行完毕释放所有资源。
简述一下 RDD?
RDD(Resilient Distributed Dataset) 是 Spark 的核心数据结构,具有以下特点:
- 容错性:通过“血统”(Lineage)信息恢复数据。
- 分布式:数据分布在多个节点,以分区形式存储。
- 不可变性:创建后内容不可变,操作会生成新的RDD。
- 操作类型:
- 转换操作:如
map、filter,生成新RDD。 - 行动操作:如
collect、count,返回结果或保存数据。
- 转换操作:如
RDD是弹性分布式数据集,弹性指什么
- 数据容错性,当某个RDD发生故障导致数据丢失时,RDD可以通过其血缘机制重新计算丢失的数据分区,而不需要进行频繁的数据冗余备份和复杂的检查点操作,从而实现数据的自我恢复和容错
- 动态调整性,RDD的数据可动态划分为多个分区,用户可通过 repartition 或 coalesce 调整分区数量,优化并行度以适�应资源变化
RDD 算子分类?
RDD 的算子主要分为两类:转换操作(Transformation) 和 行动操作(Action)
转换操作:是惰性执行的,它们对 RDD 进行操作并返回一个新的 RDD。这些操作不会立即执行
例如:map(),filter(),flatmap(),maptitions(),union,join
**行动操作:**触发实际计算的操作,它们会返回一个值或把结果写入外部存储
例如:collcet(),count(),take(n),saveAsTextFile(path),foreach(func)
RDD 的宽依赖和窄依赖
在Spark中,RDD(弹性分布式数据集)之间的依赖关系分为两种类型:宽依赖(Wide Dependency)和窄依赖(Narrow Dependency)
窄依赖:指的是每一个父RDD的Partition最多被子RDD的一个Partition使用。
- 无 shuffle:数据在本地移动,无需跨节点传输。
- 阶段划分:多个操作可合并为一个阶段(stage)
- 容错代价:仅重新计算丢失分区的父分区
- 算子:map(), filter(), flatMap(), union(), coalesce()
宽依赖:父RDD的每个分区可能被子RDD的多个分区所使用,关系复杂且可能涉及多对多的数据交换。
- 需要Shuffle:数据需跨节点重分区,网络传输开销大
- 阶段划分:Spark以此划分Stage(Stage边界),需等待前一阶段完成
- 容错复杂:若子分区丢失,需重新计算多个父分区甚至全部分区。
- 算子:
groupByKey(),reduceByKey(),join(),sortByKey(),**cogroup()**
RDD 持久化化原理
- 惰性存储:
cache()/persist()仅标记 RDD 需要持久化,真正存储发生在 **第一次行动操作(Action)**后 cache()是persist()的一种简化方式,cache()的底层就是调用persist()的无参版本persist(MEMORY_ONLY),将数据持久化到内存中- 存储级别
- MEMORY_ONLY: RDD 存储在内存中,如果内存不足,部分数据可能会被丢弃
- MEMORY_AND_DISK:优先将 RDD 存储在内存中,如果内存不足,将剩余数据存储到磁盘。
- DISK_ONLY:仅将 RDD 存储在磁盘中
- 还可以设置序列化选项,如
MEMORY_ONLY_SER和MEMORY_AND_DISK_SER,将数据以序列化格式存储,以节省空间
- 容错机制:
- 如果持久化的 RDD 分区丢失(例如节点故障),Spark 会利用 RDD 的“血统”(Lineage)信息重新计算该分区,而不需要从头开始计算整个 RDD
持久化机制
持久化只是将数据保存在BlockManager中,但是RDD的lineage(血缘关系,依赖关系)是不变的。但是checkpoint执行完之后,rdd已经没有之前所谓的依赖rdd了,而只有一个强行为其设置的checkpointRDD,checkpoint之后rdd的lineage就改变了。
持久化的数据丢失的可能性更大,因为节点的故障会导致磁盘、内存的数据丢失。但是checkpoint的数据通常是保存在高可用的文件系统中,比如HDFS中,所以数据丢失可能性比较低
RDD 累加器和广播变量
在默认情况下,当 Spark 在集群的多个不同节点的多个任务上并行运行一个函数时,它会把函数中涉及到的每个变量,在每个任务上都生成一个副本。但是,有时候需要在多个任务之间共享变量,或者在任务(Task)和任务控制节点(Driver Program)之间共享变量。
为了满足这种需求,Spark 提供了两种类型的变量:
-
累加器 accumulators:累加器支持在所有不同节点之间进行累加计算(比如计数或者求和)。
-
广播变量 broadcast variables:广播变量用来把变量在所有节点的内存之间进行共享,在每个机器上缓存一个只读的变量,而不是为机器上的每个任务都生成一个副本。
DataFrame和RDD的区别
DF存储二维表结构(必须结构化),RDD则不限制存储结构;
DF可以自动优化,RDD则不能自动优化;
DF底层依然是基于RDD实现的。
讲讲广播变量底层实现
- 创建广播变量:在 Driver 端,使用
sc.broadcast()方法创建广播变量,将数据封装在广播变量对象中。数据会被序列化,为后续传输做准备。 - 广播数据到 Executor 节点:
- 分层传播:广播机制采用类似 BitTorrent 协议的分层传播方式。Driver 首先将广播的数据块传输到一部分 Executor,这些 Executor 再将数据块传递给其他节点。这种方式可以减少网络带宽的占用。
- 数据存储:每个 Executor 接收到数据后,会将数据存储在内存或磁盘中。默认情况下,数据会先尝试存储在内存中,如果内存不足,则会溢写到磁盘。
- 任务读取广播数据:当任务在 Executor 上运行时,会先检查本地是否已经缓存了所需的广播数据。如果存在,则直接从本地读取;如果不存在,则会通过网络从其他节点获取。
- 销毁广播变量:在计算完成后,可以通过
unpersist()方法释放广播变量的数据,但保留元数据,以便后续需要时重新加载;也可以通过destroy()方法彻底销毁广播变量及其所有相关数据,释放内存和存储资源
Spark 广播变量的实现和原理
实现:调用SparkContext的broadcast(v)函数即可。
原理:将要发送的数据向每个executor发一份只读数据,而不是向task发送,因此节省了很多时间。
使用场景:任务跨多个Stage,因为执行任务前Spark就会将一个Stage所需数据发到所在节点,因此单个Stage所
用数据不必再通过广播发送。
什么是 Lineage?
Lineage是Spark RDD的核心特性之一,记录了RDD通过转换操作(如map、filter、join等)从父RDD生成的完整依赖链。其主要作用包括:
- 容错恢复:当RDD分区数据丢失时,可通过Lineage回溯父RDD重新计算,避免全量数据恢复的开销
- 逻辑执行计划:Lineage本质是RDD的DAG(有向无环图),描述了数据转换的完整路径,是任务调度的基础
- 粗粒度记录:Lineage仅记录转换操作(如
map、reduceByKey),而非具体数据值,属于粗粒度容错机制
checkpoint检查点机制
应用场景:当spark应用程序特别复杂,从初始的RDD开始到最后整个应用程序完成有很多的步骤,而且整个应用运行时间特别长,这种情况下就比较适合使用checkpoint功能。
原因:对于特别复杂的Spark应用,会出现某个反复使用的RDD,即使之前持久化过但由于节点的故障导致数据丢失了,没有容错机制,所以需要重新计算一次数据。
Checkpoint首先会调用SparkContext的setCheckPointDIR()方法,设置一个容错的文件系统的目录,比如说HDFS;然后对RDD调用checkpoint()方法。之后在RDD所处的job运行��结束之后,会启动一个单独的job,来将checkpoint过的RDD数据写入之前设置的文件系统,进行高可用、容错的类持久化操作。
RDD 缓存和 checkpoint 区别?
缓存的局限性
- 缓存只是将 RDD 的数据存储在内存或磁盘中,但仍然依赖血缘链(Lineage)来恢复数据。如果血缘链中的某个 RDD 失效或被清除,缓存的数据可能无法恢复
- 如果缓存的数据丢失,Spark 需要重新计算整个血缘链来恢复数据,这可能导致重复计算,特别是在长时间运行的任务中
Checkpoint 的优势
- Checkpoint 将 RDD 的数据持久化到外部存储系统(如 HDFS),截断血缘链。这样,即使血缘链中的某些 RDD 失效,也可以从 checkpoint 位置恢复数据
- 减少恢复时间:Checkpoint 数据存储在可靠的存储系统中,恢复数据时不需要重新计算整个血缘链,从而减少恢复时间
缓存:适合频繁访问的 RDD,提供快速访问。
Checkpoint:适合长时间运行的任务和迭代算法,提供可靠的容错机制
什么是 DAG?
DAG(Directed Acyclic Graph,有向无环图)是 Spark 作业调度的核心数据结构,用于表示 RDD(弹性分布式数据集)之间的依赖关系
如何划分 Stage ?
在Spark中,Stage的划分是基于RDD之间的依赖关系(宽依赖和窄依赖)进行的,采用回溯算法
- 反向解析DAG
- 从触发Action的最后一个RDD开始,逆向遍历RDD依赖链。
- 遇到宽依赖时,将当前操作链断开,生成独立的Stage。
- Stage类型
- ShuffleMapStage:负责Shuffle数据的中间Stage,输出数据供后续Stage使用。
- ResultStage:最终Stage,执行Action操作并输出结果。
- Task生成
- 每个Stage的任务数由最后一个RDD的分区数决定。
- ShuffleMapStage的Task数等于父RDD的分区数,ResultStage的Task数由最终RDD分区数或参数(如
spark.sql.shuffle.partitions)控制
为什么反向解析 DAG?
DAG Scheduler 从 finalRDD 出发,递归调用 getDependencies() 方法,生成 Stage 列表
从最终操作(Action)向源头逆向遍历,可快速识别宽依赖(Shuffle依赖)的位置,以此作为Stage划分的边界
Spark 中的并行度等于什么?
并行度概念:spark作业中,各个stage的task的数量,也��就代表了spark作业在各个阶段stage的并行度;
-
如何设置?
-
增加 task 数据量
- 官方推荐 总核心数的 2 - 3 倍
-
增加 block 数量
- 如果读取的数据在HDFS上,增加block数,默认情况下split与block是一对一的,而split又与RDD中的partition对应,所以增加了block数,也就提高了并行度
-
算子中指定
reduceByKey(_+_, 分区数)
-
使用
repartition()或coalesce()动态调整分区-
repartition() 强制触发Shuffle,可增加或减少分区数,适用于需要均匀分布数据的场景
val mergedRdd = rdd.coalesce(50) // 合并为50个分区(无Shuffle)注意:该方法会全量重分布数据,可能增加网络开销
-
coalesce()主要用于减少分区数(默认不触发Shuffle),适合合并小文件或优化资源利用:
val mergedRdd = rdd.coalesce(50) // 合并为50个分区(无Shuffle)若需增加分区或避免数据倾斜,可设置 shuffle=true 触发Shuffle
-
-
Spark 的分区机制?
在 Spark 中,分区(Partitioning)是将数据分布到不同节点上的过程,它决定了数据的存储和计算方式。合理的分区策略可以显著提高 Spark 作业的性能,减少数据倾斜和 Shuffle 开销。
Hash Partitioning(哈希分区)
- 原理:根据键的哈希值对分区数取模来分配数据。每个键的哈希值决定了它所在的分区。
- 适用场景:适用于数据分布较为均匀的情况。
Range Partitioning(范围分区)
- 原理:根据键的范围将数据分配到不同的分区。它会采样数据以确定分区的边界,使得每个分区包含大致相同数量的键。
- 适用场景:适用于数据按顺序排列,或者数据分布不均匀的情况。
Custom Partitioning(自定义分区)
- 原理:用户可以定义自己的分区函数,根据特定的逻辑将数据分配到不同的分区。
- 适用场景:适用于有特殊分区需求的场景。
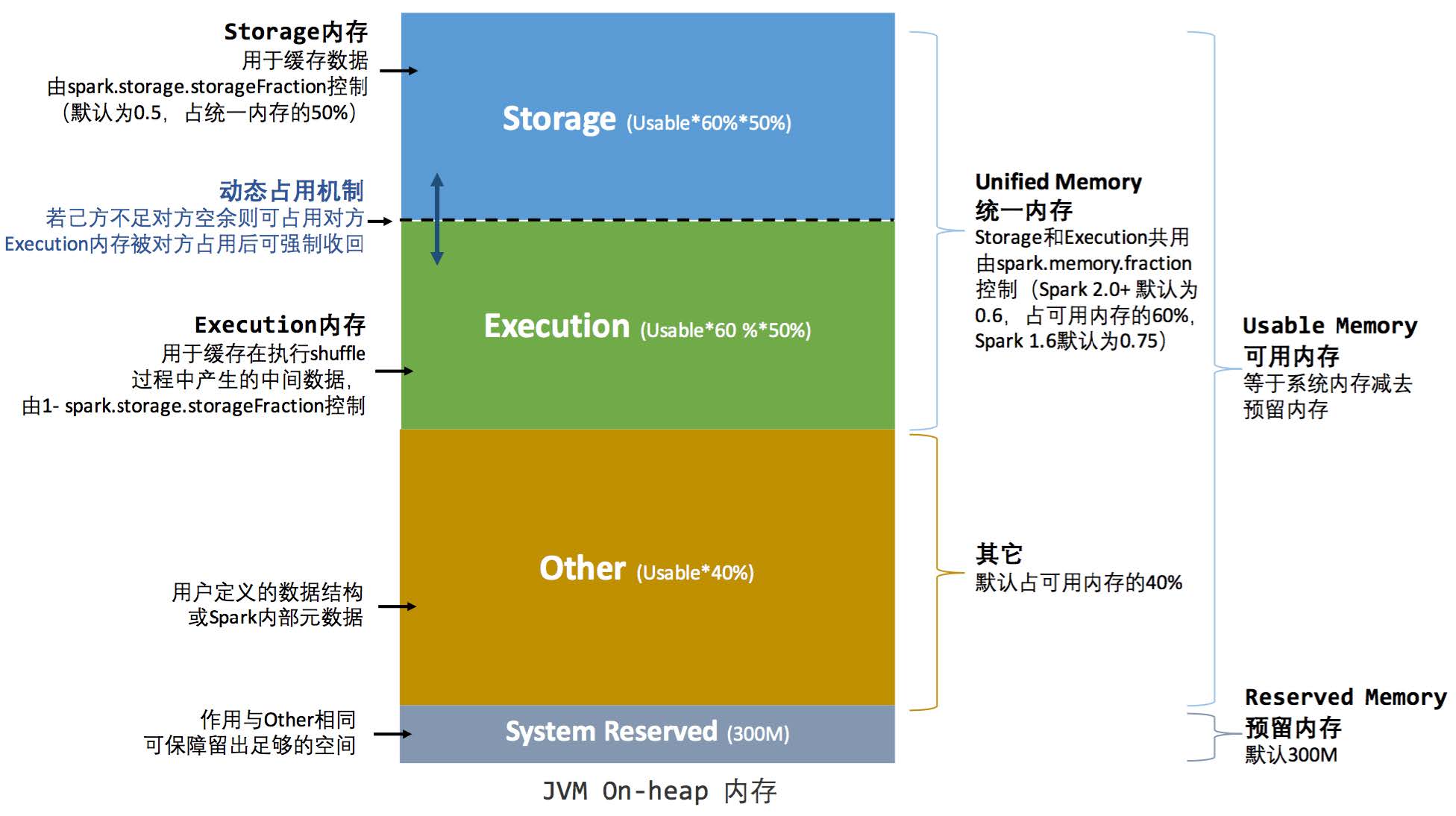
Spark 内存模型
主要分为执行内存(Execution Memory)和存储内存(Storage Memory)。下面我将详细解释Spark的内存分配、管理、优化以及内存不足时的处理机制。
内存分配
- 堆内内存与堆外内存:
- 堆内内存(On-heap Memory):用于存储Java对象,由JVM管理。
- 堆外内存(Off-heap Memory):不在JVM内申请,而是直接向操作系统申请内存,可以避免频繁的GC扫描和回收,提升处理性能。
- 执行内存与存储内存:
- 执行内存:主要用于存放Shuffle、Join、Sort、Aggregation等计算过程中的临时数据。
- 存储内存:主要用于缓存和传播内部数据,如RDD的持久化数据。
- 内存分配策略:
- 静态内存管理(Static Memory Manager):在Spark 1.6之前使用,存储内存、执行内存和其他内存的大小在Spark应用程序运行期间均为固定。
- 统一内存管理(Unified Memory Manager):Spark 1.6之后引入,存储内存和执行内存共享同一块空间,可以动态占用对方的空闲区域。
内存管理
- 内存管理接口:Spark为执行内存和存储内存的管理提供了统一的接口——MemoryManager。
- 动态调整:在统一内存管理下,存储内存和执行内存可以根据需要动态调整,提高内存利用率。
内存优化
- 合理使用缓存:对于经常需要重复计算的数据,可以使用缓存功能,减少计算开销。
- 选择合适的持久化级别:根据数据访问频率和内存大小,选择合适的持久化级别,如MEMORY_ONLY、MEMORY_AND_DISK等。
- 减少数据序列化:尽量使用Kryo序列化器,减少数据序列化开销。
- 避免频繁的Shuffle操作:合理设计数据分区,减少数据Shuffle过程。
内存不足处理机制
- Spill to Disk:当执行内存不足时,Spark会将一部分数据溢写到磁盘,以释放内存空间。
- Eviction:当存储内存不足时,Spark会根据LRU(Least Recently Used)算法淘汰最近最少使用的数据。
- 动态调整内存比例:在Spark 2.x版本之后,支持动态调整执行内存和存储内存之间的比例,以更好地利用资源。
统一内存管理
Spark 2.0 之后引入统一内存管理机制,与静态内存管理的区别在于存储内存和执行内存共享同一块空间,可以动态
占用对方的空闲区域,统一内存管理的堆内内存结构如下图所示:
堆外��内存分配较为简单,只有存储内存和执行内存。可用的执行内存和存储内存占用的空间大小直接由参数
spark.memory.storageFraction 决定
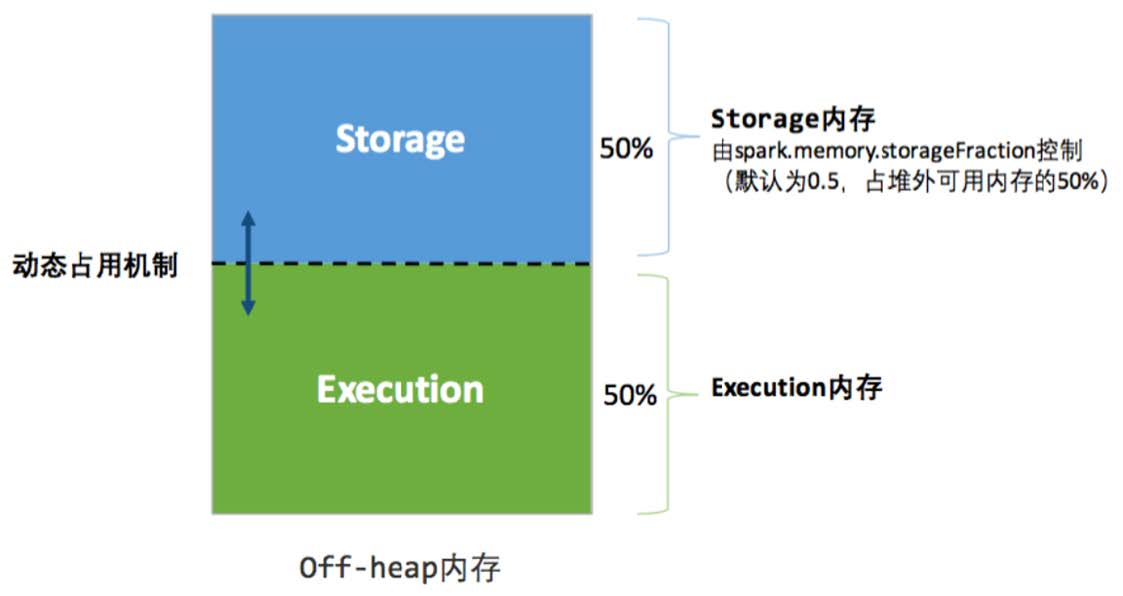
在执行过程中:执行内存的优先级 > 存储内存的优先级
凭借统一内存管理机制,Spark 在一定程度上提高了堆内和堆外内存资源的利用率,降低了开发者维护 Spark 内存的
难度,但并不意味着开发者可以高枕无忧。如果存储内存的空间太大或者说缓存的数据过多,反而会导致频繁的全量
垃圾回收,降低任务执行时的性能,因为缓存的 RDD 数据通常都是长期驻留内存的。
Spark shuffle 有哪几种?
Spark Shuffle 分为两种:一种是基于 Hash 的 Shuffle;另一种是基于 Sort 的 Shuffle
Hash Shuffle:
- 将数据按照分区键进行哈希计算,将相同哈希值的数据发送到同一个 Reducer,实现简单
- 每个任务为每个下游任务创建一个磁盘文件,可能会产生大量小文件。未经优化时,磁盘 I/O 操作频繁,性能较差。
Sort Shuffle:
- 在 Map 端对数据进行排序,然后按照排序后的顺序将数据发送到 Reducer。排序可以减少 Reduce 端的合并开销。
- 每个任务将数据写入一个或多个临时文件,最后合并成一个文件,并创建索引文件
Tungsten Sort Shuffle:Sort Shuffle 的优化��版本,利用 Tungsten 的内存管理技术以及二进制处理加速 Shuffle,减少内存占用和 GC 压力
Push-Based Shuffle (Spark 3.0+):在 Map 阶段将部分 Shuffle 数据直接推送到下游节点或第三方存储,减少 Reduce 端的拉取压力
Hash Shuffle Manager:适用于数据分布均匀且 Shuffle Read Task 数量较少的场景,可通过 Consolidate 机制优化。
Sort Shuffle Manager:适用于大多数场景,默认使用,可通过 Bypass 机制避免不必要的排序开销。
Tungsten Sort Shuffle:在内存管理优化方面表现出色,减少 GC 压力。
Push-Based Shuffle:适合大规模和长尾任务,能有效减少数据倾斜问题。
sortshuffle一定会排序吗
在 Spark 的 Sort Shuffle Manager 中,默认情况下数据会被排序,但在特定条件下可以跳过排序。具体来说:
- 默认行为:
- Sort Shuffle Manager 在 Map 端对数据进行排序,然后将排序后的数据写入磁盘。这是为了在 Reduce 端能够高效地读取和合并数据。
- Bypass 机制:
- 当 Shuffle 的分区数(partitions)小于等于
spark.shuffle.sort.bypassMergeThreshold(默认值为 200)时,Sort Shuffle Manager 会跳过排序步骤。 - 此外,Bypass 机制仅适用于非聚合类的 Shuffle 算子(如
groupByKey、reduceByKey等聚合操作不适用)。
- 当 Shuffle 的分区数(partitions)小于等于
- 触发条件总结:
- 分区数小于等于阈值:
spark.shuffle.sort.bypassMergeThreshold。 - 非聚合类 Shuffle 算子:如
mapPartitions等非聚合操作。
- 分区数小于等于阈值:
Sort Shuffle Manager 在默认情况下会对数据进行排序,但在满足特定条件(分区数较少且不是聚合类操作)时,可以通过 Bypass 机制跳过排序步骤。