Spark SQL
Spark SQL是Apache Spark中的一个重要模块,专门用于处理结构化数据
Spark SQL 解析过程
Spark SQL对SQL语句的处理和关系型数据库类似,即词法/语法解析、绑定、优化、执行。Spark SQL会先将SQL语句解析成一棵树,然后使用规则(Rule)对Tree进行绑定、优化等处理过程。Spark SQL由Core、Catalyst、Hive、Hive-ThriftServer四部分构成:
- Core: 负责处理数据的输入和输出,如获取数据,查询结果输出成DataFrame等
- Catalyst: 负责处理整个查询过程,包括解析、绑定、优化等
- Hive: 负责对Hive数据进行处理
- Hive-ThriftServer: 主要用于对Hive的访问
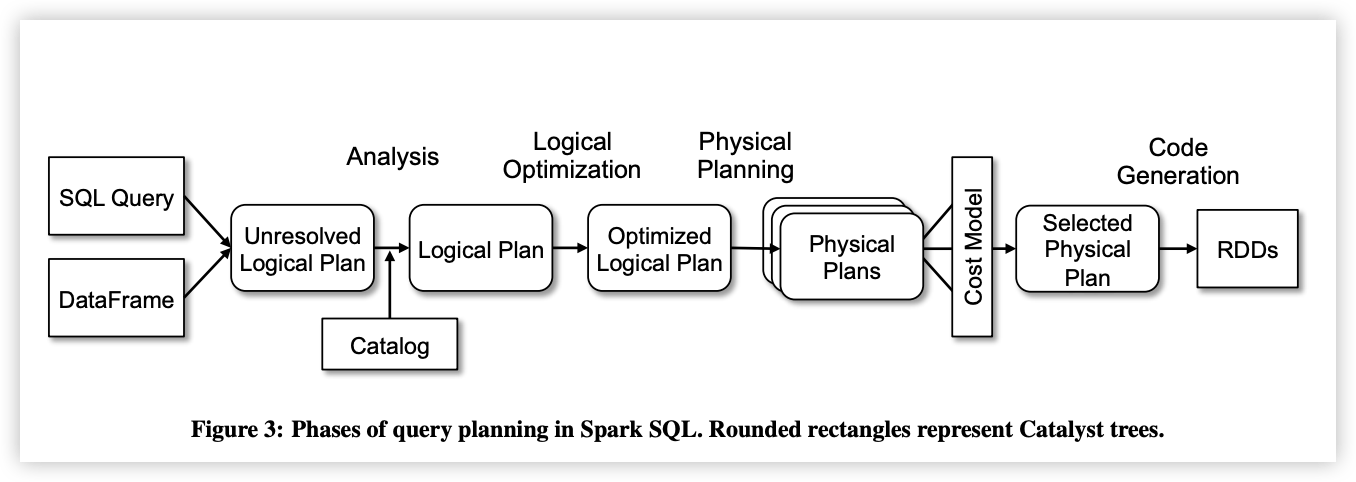
SparkSQL的解析过程大致可以分为以下几个步骤:
- 解析用户的SQL语句:将SQL字符串转换为逻辑计划。
- 优化逻辑计划:通过各种优化技术提升执行效率。
- 生成物理计划:将优化后的逻辑计划转化为可以执行的物理操作。
- 执行物理计划:将最终的物理计划应用到数据源上进行计算。
在Spark SQL中,UDF(用户自定义函数)是用于扩展SQL功能的重要工具,它允许用户执行自定义的数据转换和操作。UDF主要分为以下几种:
-
**UDF(User-Defined-Function)**:
- 功能:这是最基本的自定义函数,通常接收一行数据作为输入,并返回一个结果。例如,可以将字符串转换为特定格式或计算字符串的长度。
- 使用方法:
- 定义一个继承自
UDF1(或UDF2、UDF3等,取决于输入参数的数量)的类,并实现call方法。 - 使用
SparkSession的udf.register方法注册自定义函数。 - 在SQL查询中调用已注册的UDF。
- 定义一个继承自
-
**UDAF(User-Defined Aggregation Function)**:
-
功能:用户自定义聚合函数,通常用于在
GROUP BY操作后对数据进行聚合计算,如自定义的求和、平均值等。 -
使用方法
(以Spark 2.x为例):
- 创建一个继承自
UserDefinedAggregateFunction的类,并实现其中的多个方法,包括inputSchema、bufferSchema、dataType、deterministic、initialize、update、merge和evaluate。 - 使用
SparkSession的udf.register方法(或通过其他方式)注册自定义聚合函数。 - 在SQL查询中使用该聚合函数。
- 创建一个继承自
注意:Spark 3.x推荐使用
Aggregator来自定义UDAF,这种方式属于强类型的Dataset方式,比继承UserDefinedAggregateFunction更加灵活和高效。 -